Feed aggregator
A Ransomware Negotiator Was Working for a Ransomware Gang
Someone pleaded guilty to secretly working for a ransomware gang as he negotiated ransomware payments for clients.
Why your code is safe from Copy Fail on Fastly Compute
Kubernetes v1.36: In-Place Vertical Scaling for Pod-Level Resources Graduates to Beta
Following the graduation of Pod-Level Resources to Beta in v1.34 and the General Availability (GA) of In-Place Pod Vertical Scaling in v1.35, the Kubernetes community is thrilled to announce that In-Place Pod-Level Resources Vertical Scaling has graduated to Beta in v1.36!
This feature is now enabled by default via the InPlacePodLevelResourcesVerticalScaling feature gate. It allows users to update the aggregate Pod resource budget (.spec.resources) for a running Pod, often without requiring a container restart.
Why Pod-level in-place resize?
The Pod-level resource model simplified management for complex Pods (such as those with sidecars) by allowing containers to share a collective pool of resources. In v1.36, you can now adjust this aggregate boundary on-the-fly.
This is particularly useful for Pods where containers do not have individual limits defined. These containers automatically scale their effective boundaries to fit the newly resized Pod-level dimensions, allowing you to expand the shared pool during peak demand without manual per-container recalculations.
Resource inheritance and the resizePolicy
When a Pod-level resize is initiated, the Kubelet treats the change as a resize event for every container that inherits its limits from the Pod-level budget. To determine whether a restart is required, the Kubelet consults the resizePolicy defined within individual containers:
- Non-disruptive Updates: If a container's
restartPolicyis set toNotRequired, the Kubelet attempts to update the cgroup limits dynamically via the Container Runtime Interface (CRI). - Disruptive Updates: If set to
RestartContainer, the container will be restarted to apply the new aggregate boundary safely.
Note: Currently,
resizePolicyis not supported at the Pod level. The Kubelet always defers to individual container settings to decide if an update can be applied in-place or requires a restart.
Example: Scaling a shared resource pool
In this scenario, a Pod is defined with a 2 CPU pod-level limit. Because the individual containers do not have their own limits defined, they share this total pool.
1. Initial Pod specification
apiVersion: v1
kind: Pod
metadata:
name: shared-pool-app
spec:
resources: # Pod-level limits
limits:
cpu: "2"
memory: "4Gi"
containers:
- name: main-app
image: my-app:v1
resizePolicy: [{resourceName: "cpu", restartPolicy: "NotRequired"}]
- name: sidecar
image: logger:v1
resizePolicy: [{resourceName: "cpu", restartPolicy: "NotRequired"}]
2. The resize operation
To double the CPU capacity to 4 CPUs, apply a patch using the resize subresource:
kubectl patch pod shared-pool-app --subresource resize --patch \
'{"spec":{"resources":{"limits":{"cpu":"4"}}}}'
Node-Level reality: feasibility and safety
Applying a resize patch is only the first step. The Kubelet performs several checks and follows a specific sequence to ensure node stability:
1. The feasibility check
Before admitting a resize, the Kubelet verifies if the new aggregate request fits within the Node's allocatable capacity. If the Node is overcommitted, the resize is not ignored; instead, the PodResizePending condition will reflect a Deferred or Infeasible status, providing immediate feedback on why the "envelope" hasn't grown.
2. Update sequencing
To prevent resource "overshoot", the Kubelet coordinates the cgroup updates in a specific order:
- When Increasing: The Pod-level cgroup is expanded first, creating the "room" before the individual container cgroups are enlarged.
- When Decreasing: The container cgroups are throttled first, and only then is the aggregate Pod-level cgroup shrunken.
Observability: tracking resize status
With the move to Beta, Kubernetes uses Pod Conditions to track the lifecycle of a resize:
PodResizePending: The spec is updated, but the Node hasn't admitted the change (e.g., due to capacity).PodResizeInProgress: The Node has admitted the resize (status.allocatedResources) but the changes aren't yet fully applied to the cgroups (status.resources).
status:
allocatedResources:
cpu: "4"
resources:
limits:
cpu: "4"
conditions:
- type: PodResizeInProgress
status: "True"
Constraints and requirements
- cgroup v2 Only: Required for accurate aggregate enforcement.
- CRI Support: Requires a container runtime that supports the
UpdateContainerResourcesCRI call (e.g., containerd v2.0+ or CRI-O). - Feature Gates: Requires
PodLevelResources,InPlacePodVerticalScaling,InPlacePodLevelResourcesVerticalScaling, andNodeDeclaredFeatures. - Linux Only: Currently exclusive to Linux-based nodes.
What's next?
As we move toward General Availability (GA), the community is focusing on Vertical Pod Autoscaler (VPA) Integration, enabling VPA to issue Pod-level resource recommendations and trigger in-place actuation automatically.
Getting started and providing feedback
We encourage you to test this feature and provide feedback via the standard Kubernetes communication channels:
Anti-DDoS Firm Heaped Attacks on Brazilian ISPs
A Brazilian tech firm that specializes in protecting networks from distributed denial-of-service (DDoS) attacks has been enabling a botnet responsible for an extended campaign of massive DDoS attacks against other network operators in Brazil, KrebsOnSecurity has learned. The firm’s chief executive says the malicious activity resulted from a security breach and was likely the work of a competitor trying to tarnish his company’s public image.

An Archer AX21 router from TP-Link. Image: tp-link.com.
For the past several years, security experts have tracked a series of massive DDoS attacks originating from Brazil and solely targeting Brazilian ISPs. Until recently, it was less than clear who or what was behind these digital sieges. That changed earlier this month when a trusted source who asked to remain anonymous shared a curious file archive that was exposed in an open directory online.
The exposed archive contained several Portuguese-language malicious programs written in Python. It also included the private SSH authentication keys belonging to the CEO of Huge Networks, a Brazilian ISP that primarily offers DDoS protection to other Brazilian network operators.
Founded in Miami, Fla. in 2014, Huge Networks’s operations are centered in Brazil. The company originated from protecting game servers against DDoS attacks and evolved into an ISP-focused DDoS mitigation provider. It does not appear in any public abuse complaints and is not associated with any known DDoS-for-hire services.
Nevertheless, the exposed archive shows that a Brazil-based threat actor maintained root access to Huge Networks infrastructure and built a powerful DDoS botnet by routinely mass-scanning the Internet for insecure Internet routers and unmanaged domain name system (DNS) servers on the Web that could be enlisted in attacks.
DNS is what allows Internet users to reach websites by typing familiar domain names instead of the associated IP addresses. Ideally, DNS servers only provide answers to machines within a trusted domain. But so-called “DNS reflection” attacks rely on DNS servers that are (mis)configured to accept queries from anywhere on the Web. Attackers can send spoofed DNS queries to these servers so that the request appears to come from the target’s network. That way, when the DNS servers respond, they reply to the spoofed (targeted) address.
By taking advantage of an extension to the DNS protocol that enables large DNS messages, botmasters can dramatically boost the size and impact of a reflection attack — crafting DNS queries so that the responses are much bigger than the requests. For example, an attacker could compose a DNS request of less than 100 bytes, prompting a response that is 60-70 times as large. This amplification effect is especially pronounced when the perpetrators can query many DNS servers with these spoofed requests from tens of thousands of compromised devices simultaneously.
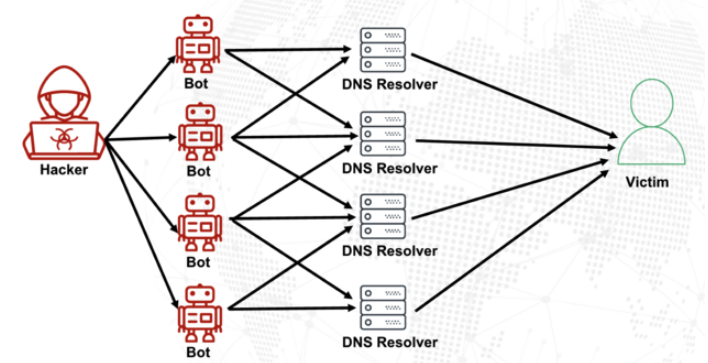
A DNS amplification and reflection attack, illustrated. Image: veracara.digicert.com.
The exposed file archive includes a command-line history showing exactly how this attacker built and maintained a powerful botnet by scouring the Internet for TP-Link Archer AX21 routers. Specifically, the botnet seeks out TP-Link devices that remain vulnerable to CVE-2023-1389, an unauthenticated command injection vulnerability that was patched back in April 2023.
Malicious domains in the exposed Python attack scripts included DNS lookups for hikylover[.]st, and c.loyaltyservices[.]lol, both domains that have been flagged in the past year as control servers for an Internet of Things (IoT) botnet powered by a Mirai malware variant.
The leaked archive shows the botmaster coordinated their scanning from a Digital Ocean server that has been flagged for abusive activity hundreds of times in the past year. The Python scripts invoke multiple Internet addresses assigned to Huge Networks that were used to identify targets and execute DDoS campaigns. The attacks were strictly limited to Brazilian IP address ranges, and the scripts show that each selected IP address prefix was attacked for 10-60 seconds with four parallel processes per host before the botnet moved on to the next target.
The archive also shows these malicious Python scripts relied on private SSH keys belonging to Huge Networks’s CEO, Erick Nascimento. Reached for comment about the files, Mr. Nascimento said he did not write the attack programs and that he didn’t realize the extent of the DDoS campaigns until contacted by KrebsOnSecurity.
“We received and notified many Tier 1 upstreams regarding very very large DDoS attacks against small ISPs,” Nascimento said. “We didn’t dig deep enough at the time, and what you sent makes that clear.”
Nascimento said the unauthorized activity is likely related to a digital intrusion first detected in January 2026 that compromised two of the company’s development servers, as well as his personal SSH keys. But he said there’s no evidence those keys were used after January.
“We notified the team in writing the same day, wiped the boxes, and rotated keys,” Nascimento said, sharing a screenshot of a January 11 notification from Digital Ocean. “All documented internally.”
Mr. Nascimento said Huge Networks has since engaged a third-party network forensics firm to investigate further.
“Our working assessment so far is that this all started with a single internal compromise — one pivot point that gave the attacker downstream access to some resources, including a legacy personal droplet of mine,” he wrote.
“The compromise happened through a bastion/jump server that several people had access to,” Nascimento continued. “Digital Ocean flagged the droplet on January 11 — compromised due to a leaked SSH key, in their wording — I was traveling at the time and addressed it on return. That droplet was deprecated and destroyed, and it was never part of Huge Networks infrastructure.”
The malicious software that powers the botnet of TP-Link devices used in the DDoS attacks on Brazilian ISPs is based on Mirai, a malware strain that made its public debut in September 2016 by launching a then record-smashing DDoS attack that kept this website offline for four days. In January 2017, KrebsOnSecurity identified the Mirai authors as the co-owners of a DDoS mitigation firm that was using the botnet to attack gaming servers and scare up new clients.
In May 2025, KrebsOnSecurity was hit by another Mirai-based DDoS that Google called the largest attack it had ever mitigated. That report implicated a 20-something Brazilian man who was running a DDoS mitigation company as well as several DDoS-for-hire services that have since been seized by the FBI.
Nascimento flatly denied being involved in DDoS attacks against Brazilian operators to generate business for his company’s services.
“We don’t run DDoS attacks against Brazilian operators to sell protection,” Nascimento wrote in response to questions. “Our sales model is mostly inbound and through channel integrator, distributors, partners — not active prospecting based on market incidents. The targets in the scripts you received are small regional providers, the vast majority of which are neither in our customer base nor in our commercial pipeline — a fact verifiable through public sources like QRator.”
Nascimento maintains he has “strong evidence stored on the blockchain” that this was all done by a competitor. As for who that competitor might be, the CEO wouldn’t say.
“I would love to share this with you, but it could not be published as it would lose the surprise factor against my dishonest competitor,” he explained. “Coincidentally or not, your contact happened a week before an important event – one that this competitor has NEVER participated in (and it’s a traditional event in the sector). And this year, they will be participating. Strange, isn’t it?”
Strange indeed.
Fast16 Malware
Researchers have reverse-engineered a piece of malware named Fast16. It’s almost certainly state-sponsored, probably US in origin, and was deployed against Iran years before Stuxnet:
“…the Fast16 malware was designed to carry out the most subtle form of sabotage ever seen in an in-the-wild malware tool: By automatically spreading across networks and then silently manipulating computation processes in certain software applications that perform high-precision mathematical calculations and simulate physical phenomena, Fast16 can alter the results of those programs to cause failures that range from faulty research results to catastrophic damage to real-world equipment.”...
Announcing Vitess 24
Announcing Vitess 24
Announcing Vitess 24
Kubernetes v1.36: Tiered Memory Protection with Memory QoS
On behalf of SIG Node, we are pleased to announce updates to the Memory QoS
feature (alpha) in Kubernetes v1.36. Memory QoS uses the cgroup v2 memory
controller to give the kernel better guidance on how to treat container memory.
It was first introduced in v1.22 and updated in v1.27. In Kubernetes v1.36, we're introducing: opt-in memory reservation, tiered
protection by QoS class, observability metrics, and kernel-version warning for memory.high.
What's new in v1.36
Opt-in memory reservation with memoryReservationPolicy
v1.36 separates throttling from reservation. Enabling the feature gate turns on
memory.high throttling (the kubelet sets memory.high based on
memoryThrottlingFactor, default 0.9), but memory reservation is now controlled
by a separate kubelet configuration field:
None(default): nomemory.minormemory.lowis written. Throttling viamemory.highstill works.TieredReservation: the kubelet writes tiered memory protection based on the Pod's QoS class:
Guaranteed Pods get hard protection via memory.min. For example, a
Guaranteed Pod requesting 512 MiB of memory results in:
$ cat /sys/fs/cgroup/kubepods.slice/kubepods-pod6a4f2e3b_1c9d_4a5e_8f7b_2d3e4f5a6b7c.slice/memory.min
536870912
The kernel will not reclaim this memory under any circumstances. If it cannot honor the guarantee, it invokes the OOM killer on other processes to free pages.
Burstable Pods get soft protection via memory.low. For the same 512 MiB
request on a Burstable Pod:
$ cat /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod8b3c7d2e_4f5a_6b7c_9d1e_3f4a5b6c7d8e.slice/memory.low
536870912
The kernel avoids reclaiming this memory under normal pressure, but may reclaim it if the alternative is a system-wide OOM.
BestEffort Pods get neither memory.min nor memory.low. Their memory
remains fully reclaimable.
Comparison with v1.27 behavior
In earlier versions, enabling the MemoryQoS feature gate immediately set memory.min for every container with a memory request. memory.min is a hard reservation that the kernel will not reclaim, regardless of memory pressure.
Consider a node with 8 GiB of RAM where Burstable Pod requests total 7 GiB. In earlier versions, that 7 GiB would be locked as memory.min, leaving little headroom for the kernel, system daemons, or BestEffort workloads and increasing the risk of OOM kills.
With v1.36 tiered reservation, those Burstable requests map to memory.low instead of memory.min. Under normal pressure, the kernel still protects that memory, but under extreme pressure it can reclaim part of it to avoid system-wide OOM. Only Guaranteed Pods use memory.min, which keeps hard reservation lower.
With memoryReservationPolicy in v1.36, you can enable throttling first, observe workload behavior, and opt into reservation when your node has enough headroom.
Observability metrics
Two alpha-stability metrics are exposed on the kubelet /metrics endpoint:
kubelet_memory_qos_node_memory_min_bytes
Total memory.min across Guaranteed Pods
kubelet_memory_qos_node_memory_low_bytes
Total memory.low across Burstable Pods
These are useful for capacity planning. If kubelet_memory_qos_node_memory_min_bytes
is creeping toward your node's physical memory, you know hard reservation is
getting tight.
$ curl -sk https://localhost:10250/metrics | grep memory_qos
# HELP kubelet_memory_qos_node_memory_min_bytes [ALPHA] Total memory.min in bytes for Guaranteed pods
kubelet_memory_qos_node_memory_min_bytes 5.36870912e+08
# HELP kubelet_memory_qos_node_memory_low_bytes [ALPHA] Total memory.low in bytes for Burstable pods
kubelet_memory_qos_node_memory_low_bytes 2.147483648e+09
Kernel version check
On kernels older than 5.9, memory.high throttling can trigger the
kernel livelock issue. The bug was fixed
in kernel 5.9. In v1.36, when the feature gate is enabled, the kubelet checks the
kernel version at startup and logs a warning if it is below 5.9. The feature
continues to work — this is informational, not a hard block.
How Kubernetes maps Memory QoS to cgroup v2
Memory QoS uses four cgroup v2 memory controller interfaces:
memory.max: hard memory limit — unchanged from previous versionsmemory.min: hard memory protection — withTieredReservation, set only for Guaranteed Podsmemory.low: soft memory protection — set for Burstable Pods withTieredReservationmemory.high: memory throttling threshold — unchanged from previous versions
The following table shows how Kubernetes container resources map to cgroup v2
interfaces when memoryReservationPolicy: TieredReservation is configured.
With the default memoryReservationPolicy: None, no memory.min or
memory.low values are set.
requests.memory(hard protection) Not set Not set
(requests == limits, so throttling is not useful) Set to
limits.memory
Burstable
Not set
Set to requests.memory(soft protection) Calculated based on
formula with throttling factor Set to
limits.memory(if specified) BestEffort Not set Not set Calculated based on
node allocatable memory Not set
Cgroup hierarchy
cgroup v2 requires that a parent cgroup's memory protection is at least as
large as the sum of its children's. The kubelet maintains this by setting
memory.min on the kubepods root cgroup to the sum of all Guaranteed and
Burstable Pod memory requests, and memory.low on the Burstable QoS cgroup
to the sum of all Burstable Pod memory requests. This way the kernel can
enforce the per-container and per-pod protection values correctly.
The kubelet manages pod-level and QoS-class cgroups directly using the runc libcontainer library, while container-level cgroups are managed by the container runtime (containerd or CRI-O).
How do I use it?
Prerequisites
- Kubernetes v1.36 or later
- Linux with cgroup v2. Kernel 5.9 or higher is recommended — earlier kernels
work but may experience the livelock issue. You can verify cgroup v2 is
active by running
mount | grep cgroup2. - A container runtime that supports cgroup v2 (containerd 1.6+, CRI-O 1.22+)
Configuration
To enable Memory QoS with tiered protection:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
MemoryQoS: true
memoryReservationPolicy: TieredReservation # Options: None (default), TieredReservation
memoryThrottlingFactor: 0.9 # Optional: default is 0.9
If you want memory.high throttling without memory protection, omit
memoryReservationPolicy or set it to None:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
MemoryQoS: true
memoryReservationPolicy: None # This is the default
How can I learn more?
- KEP-2570: Memory QoS
- Pod Quality of Service Classes
- Managing Resources for Containers
- Kubernetes cgroups v2 support
- Linux kernel cgroups v2 documentation
Getting involved
This feature is driven by SIG Node. If you are interested in contributing or have feedback, you can find us on Slack (#sig-node), the mailing list, or at the regular SIG Node meetings. Please file bugs at kubernetes/kubernetes and enhancement proposals at kubernetes/enhancements.
Claude Mythos Has Found 271 Zero-Days in Firefox
That’s a lot. No, it’s an extraordinary number:
Since February, the Firefox team has been working around the clock using frontier AI models to find and fix latent security vulnerabilities in the browser. We wrote previously about our collaboration with Anthropic to scan Firefox with Opus 4.6, which led to fixes for 22 security-sensitive bugs in Firefox 148.
As part of our continued collaboration with Anthropic, we had the opportunity to apply an early version of Claude Mythos Preview to Firefox. This week’s release of Firefox 150 includes fixes for 271 vulnerabilities identified during this initial evaluation...
Myth or Marvel: Claude Mythos and What it Means for Security
Kubernetes v1.36: Staleness Mitigation and Observability for Controllers
Staleness in Kubernetes controllers is a problem that affects many controllers, and is something may affect controller behavior in subtle ways. It is usually not until it is too late, when a controller in production has already taken incorrect action, that staleness is found to be an issue due to some underlying assumption made by the controller author. Some issues caused by staleness include controllers taking incorrect actions, controllers not taking action when they should, and controllers taking too long to take action. I am excited to announce that Kubernetes v1.36 includes new features that help mitigate staleness in controllers and provide better observability into controller behavior.
What is staleness?
Staleness in controllers comes from an outdated view of the world inside of the controller cache. In order to provide a fast user experience, controllers typically maintain a local cache of the state of the cluster. This cache is populated by watching the Kubernetes API server for changes to objects that the controller cares about. When the controller needs to take action, it will first check its cache to see if it has the latest information. If it does not, it will then update its cache by watching the API server for changes to objects that the controller cares about. This process is known as reconciliation.
However, there are some cases where the controller's cache may be outdated. For example, if the controller is restarted, it will need to rebuild its cache by watching the API server for changes to objects that the controller cares about. During this time, the controller's cache will be outdated, and it will not be able to take action. Additionally, if the API server is down, the controller's cache will not be updated, and it will not be able to take action. These are just a few examples of cases where the controller's cache may be outdated.
Improvements in 1.36
Kubernetes v1.36 includes improvements in both client-go as well as implementations of highly contended controllers in kube-controller-manager, using those client-go improvements.
client-go improvements
In client-go, the project added atomic FIFO processing (feature gate
name AtomicFIFO), which is on top of the existing FIFO queue implementation. The new approach allows for
the queue to atomically handle operations that are recieved in batches, such as the initial set of objects from a
list operation that an informer uses to populate its cache. This ensures that the queue is always in a consistent state,
even when events come out of order. Prior to this, events were added to the queue
in the order that they were received, which could lead to an inconsistent state in the cache that does not accurately reflect
the state of the cluster.
With this change, you can now ensure that the queue is always in a consistent state, even when events come out of order. To take
advantage of this, clients using client-go can now introspect into the cache to determine the latest resource version that the
controller cache has seen. This is done with the newly added function LastStoreSyncResourceVersion() implemented on the Store
interface here. This function is the basis for the staleness mitigation
features in kube-controller-manager.
kube-controller-manager improvements
In kube-controller-manager, the v1.36 release has added the ability for 4 different controllers to use this new capability. The controllers are:
- DaemonSet controller
- StatefulSet controller
- ReplicaSet controller
- Job controller
These controllers all act on pods, which in most cases are under the highest amount of contention in a cluster. The changes are
on by default for these controllers, and can be disabled by setting the feature gates StaleControllerConsistency<API type>
to false for the specific controller you wish to disable it for. For example, to disable the feature for the DaemonSet controller,
you would set the feature gate StaleControllerConsistencyDaemonSet to false.
When the relevant feature gate is enabled, the controller will first check the latest resource version of the cache before taking action. If the latest resource version of the cache is lower than what the controller has written to the API server for the object it is trying to reconcile, the controller will not take action. This is because the controller's cache is outdated, and it does not have the latest information about the state of the cluster.
Use for informer authors
Informer authors using client-go can also immediately take advantage of these improvements. See an example of how to use this feature
in the ReplicaSet informer. This PR shows how to use the new feature to check
if the informer's cache is stale before taking action. The client-go library provides a ConsistencyStore data structure that queries the store
and compares the latest resource version of the cache with the written resource version of the object.
The ReplicaSet controller tracks both the ReplicaSet's resource version and the resource version of the pods that the ReplicaSet manages. For a specific ReplicaSet, it tracks the latest written resource version of the pods that the ReplicaSet owns as well as any writes to the ReplicaSet itself. If the latest resource version of the cache is lower than what the controller has written to the API server for the object it is trying to reconcile, the controller will not take action. This is because the controller's cache is outdated, and it does not have the latest information about the state of the cluster.
An informer author can use the ConsistencyStore to track the latest resource version of the objects that the informer cares about.
It provides 3 main functions:
type ConsistencyStore interface {
// WroteAt records that the given object was written at the given resource version.
WroteAt(owningObj runtime.Object, uid types.UID, groupResource schema.GroupResource, resourceVersion string)
// EnsureReady returns true if the cache is up to date for the given object.
// It is used prior to reconciliation to decide whether to reconcile or not.
EnsureReady(namespacedName types.NamespacedName) bool
// Clear removes the given object from the consistency store.
// It is used when an object is deleted.
Clear(namespacedName types.NamespacedName, uid types.UID)
}
WroteAt: This function is called by the controller when it writes to the API server for an object. It is used to record the latest resource version of the object that the controller has written to the API server. TheowningObjis the object that the controller is reconciling, and theuidis the UID of that object. The resource version and GroupResource are the resource version and GroupResource of the object that the controller has written to the API server. The object is not explicitly tracked, since the controller only cares about waiting to catch up to the latest resource version of the written object.EnsureReady: This function is called by the controller to ensure that the cache is up to date for the object. It is used prior to reconciliation to decide whether to reconcile or not. It returns true if the cache is up to date for the object, and false otherwise. It will use the information provided byWroteAtto determine if the cache is up to date.Clear: This function is called by the controller when an object is deleted. It is used to remove the object from the consistency store. This is mostly used for cleanup when an object is deleted to prevent the consistency store from growing indefinitely.
The UID is used to distinguish between different objects that have the same name, such as when an object is deleted and then recreated. It is not needed for EnsureReady because the consistency store is only concerned with catching up to the latest resource version of the object, not the specific object. It is primarily used to ensure that the controller doesn't delete the entry for an object when it is recreated with a new UID.
With these 3 functions, an informer author can implement staleness mitigation in their controller.
Observability
In addition to the staleness mitigation features, the Kubernetes project has also added related instrumentation to kube-controller-manager in 1.36. These metrics are also enabled by default, and are controlled using the same set of feature gates.
Metrics
The following alpha metrics have been added to kube-controller-manager in 1.36:
stale_sync_skips_total: The number of times the controller has skipped a sync due to stale cache. This metric is exposed
for each controller that uses the staleness mitigation feature with the subsystem of the controller.
This metric is exposed by the kube-controller-manager metrics endpoint, and can be used to monitor the health of the controller.
Along with this metric, client-go also emits metrics that expose the latest resource version of every shared informer with the subsystem of the informer. This allows you to see the latest resource version of each informer, and use that to determine if the controller's cache is stale, especially great for comparing against the resource version of the API server.
This metric is named store_resource_version and has the Group, Version, and Resource as labels.
What's next?
Kubernetes SIG API Machinery is excited to continue working on this feature and hope to bring it to more controllers in the future. We are also interested in hearing your feedback on this feature. Please let us know what you think in the comments below or by opening an issue on the Kubernetes GitHub repository.
We are also working with controller-runtime to enable this set of semantics for all controllers built with controller-runtime. This will allow any controller built with controller-runtime to gain the benefits of read your own writes, without having to implement the logic themselves.
What Anthropic’s Mythos Means for the Future of Cybersecurity
Two weeks ago, Anthropic announced that its new model, Claude Mythos Preview, can autonomously find and weaponize software vulnerabilities, turning them into working exploits without expert guidance. These were vulnerabilities in key software like operating systems and internet infrastructure that thousands of software developers working on those systems failed to find. This capability will have major security implications, compromising the devices and services we use every day. As a result, Anthropic is not releasing the model to the general public, but instead to a ...
Kubernetes v1.36: Mutable Pod Resources for Suspended Jobs (beta)
Kubernetes v1.36 promotes the ability to modify container resource requests and limits in the pod template of a suspended Job to beta. First introduced as alpha in v1.35, this feature allows queue controllers and cluster administrators to adjust CPU, memory, GPU, and extended resource specifications on a Job while it is suspended, before it starts or resumes running.
Why mutable pod resources for suspended Jobs?
Batch and machine learning workloads often have resource requirements that are not precisely known at Job creation time. The optimal resource allocation depends on current cluster capacity, queue priorities, and the availability of specialized hardware like GPUs.
Before this feature, resource requirements in a Job's pod template were immutable once set. If a queue controller like Kueue determined that a suspended Job should run with different resources, the only option was to delete and recreate the Job, losing any associated metadata, status, or history. This feature also provides a way to let a specific Job instance for a CronJob progress slowly with reduced resources, rather than outright failing to run if the cluster is heavily loaded.
Consider a machine learning training Job initially requesting 4 GPUs:
apiVersion: batch/v1
kind: Job
metadata:
name: training-job-example-abcd123
labels:
app.kubernetes.io/name: trainer
spec:
suspend: true
template:
metadata:
annotations:
kubernetes.io/description: "ML training, ID abcd123"
spec:
containers:
- name: trainer
image: example-registry.example.com/training:2026-04-23T150405.678
resources:
requests:
cpu: "8"
memory: "32Gi"
example-hardware-vendor.com/gpu: "4"
limits:
cpu: "8"
memory: "32Gi"
example-hardware-vendor.com/gpu: "4"
restartPolicy: Never
A queue controller managing cluster resources might determine that only 2 GPUs are available. With this feature, the controller can update the Job's resource requests before resuming it:
apiVersion: batch/v1
kind: Job
metadata:
name: training-job-example-abcd123
labels:
app.kubernetes.io/name: trainer
spec:
suspend: true
template:
metadata:
annotations:
kubernetes.io/description: "ML training, ID abcd123"
spec:
containers:
- name: trainer
image: example-registry.example.com/training:2026-04-23T150405.678
resources:
requests:
cpu: "4"
memory: "16Gi"
example-hardware-vendor.com/gpu: "2"
limits:
cpu: "4"
memory: "16Gi"
example-hardware-vendor.com/gpu: "2"
restartPolicy: Never
Once the resources are updated, the controller resumes the Job by setting
spec.suspend to false, and the new Pods are created with the adjusted
resource specifications.
How it works
The Kubernetes API server relaxes the immutability constraint on pod template resource fields specifically for suspended Jobs. No new API types have been introduced; the existing Job and pod template structures accommodate the change through relaxed validation.
The mutable fields are:
spec.template.spec.containers[*].resources.requestsspec.template.spec.containers[*].resources.limitsspec.template.spec.initContainers[*].resources.requestsspec.template.spec.initContainers[*].resources.limits
Resource updates are permitted when the following conditions are met:
- The Job has
spec.suspendset totrue. - For a Job that was previously running and then suspended, all active
Pods must have terminated (
status.activeequals 0) before resource mutations are accepted.
Standard resource validation still applies. For example, resource limits must be greater than or equal to requests, and extended resources must be specified as whole numbers where required.
What's new in beta
With the promotion to beta in Kubernetes v1.36, the
MutablePodResourcesForSuspendedJobs feature gate is enabled by default.
This means clusters running v1.36 can use this feature without any additional
configuration on the API server.
Try it out
If your cluster is running Kubernetes v1.36 or later, this feature is available
by default. For v1.35 clusters, enable the MutablePodResourcesForSuspendedJobs
feature gate on
the kube-apiserver.
You can test it by creating a suspended Job, updating its container resources
using kubectl edit or a controller, and then resuming the Job:
# Create a suspended Job
kubectl apply -f my-job.yaml --server-side
# Edit the resource requests
kubectl edit job training-job-example-abcd123
# Resume the Job
kubectl patch job training-job-example-abcd123 -p '{"spec":{"suspend":false}}'
Considerations
Running Jobs that are suspended
If you suspend a Job that was already running, you must wait for all of that Job's active
Pods to terminate before modifying resources. The API server rejects resource
mutations while status.active is greater than zero. This prevents inconsistency
between running Pods and the updated pod template.
Pod replacement policy
When using this feature with Jobs that may have failed Pods, consider setting
podReplacementPolicy: Failed. This ensures that replacement Pods are only
created after the previous Pods have fully terminated, preventing resource
contention from overlapping Pods.
ResourceClaims
Dynamic Resource Allocation (DRA) resourceClaimTemplates remain immutable.
If your workload uses DRA, you must recreate the claim templates separately
to match any resource changes.
Getting involved
This feature was developed by SIG Apps This feature was developed by SIG Apps with input from WG Batch. Both groups welcome feedback as the feature progresses toward stable.
You can reach out through:
Medieval Encrypted Letter Decoded
Sent by a Spanish diplomat. Apparently people have been working on it since it was rediscovered in 1860.
Redefining security data: Red Hat’s new VEX experience heading to Red Hat Summit 2026
Admission Controller 1.35 Release
Friday Squid Blogging: How Squid Survived Extinction Events
Science news:
Scientists have finally cracked a long-standing mystery about squid and cuttlefish evolution by analyzing newly sequenced genomes alongside global datasets. The research reveals that these bizarre, intelligent creatures likely originated deep in the ocean over 100 million years ago, surviving mass extinction events by retreating into oxygen-rich deep-sea refuges. For millions of years, their evolution barely changed—until a dramatic post-extinction boom sparked rapid diversification as they moved into new shallow-water habitats. ...
Kubernetes v1.36: Fine-Grained Kubelet API Authorization Graduates to GA
On behalf of Kubernetes SIG Auth and SIG Node, we are pleased to announce the
graduation of fine-grained kubelet API authorization to General Availability
(GA) in Kubernetes v1.36!
The KubeletFineGrainedAuthz feature gate was introduced as an opt-in alpha
feature in Kubernetes v1.32, then graduated to beta (enabled by default) in
v1.33. Now, the feature is generally available and the feature gate is locked
to enabled. This feature enables more precise, least-privilege access control
over the kubelet's HTTPS API, replacing the need to grant the overly broad
nodes/proxy permission for common monitoring and observability use cases.
Motivation: the nodes/proxy problem
The kubelet exposes an HTTPS endpoint with several APIs that give access to data
of varying sensitivity, including pod listings, node metrics, container logs,
and, critically, the ability to execute commands inside running containers.
Prior to this feature, kubelet authorization used a coarse-grained model. When
webhook authorization was enabled, almost all kubelet API paths were mapped to a
single nodes/proxy subresource. This meant that any workload needing to read
metrics or health status from the kubelet required nodes/proxy permission,
the same permission that also grants the ability to execute arbitrary commands
in any container running on the node.
What's wrong with that?
Granting nodes/proxy to monitoring agents, log collectors, or health-checking
tools violates the principle of least privilege. If any of those workloads were
compromised, an attacker would gain the ability to run commands in every
container on the node. The nodes/proxy permission is effectively a node-level
superuser capability, and granting it broadly dramatically increases the blast
radius of a security incident.
This problem has been well understood in the community for years (see kubernetes/kubernetes#83465), and was the driving motivation behind this enhancement KEP-2862.
The nodes/proxy GET WebSocket RCE risk
The situation is more severe than it might appear at first glance. Security
researchers demonstrated in early 2026
that nodes/proxy GET alone, which is the minimal read-only permission routinely
granted to monitoring tools, can be abused to execute commands in any pod on
reachable nodes.
The root cause is a mismatch between how WebSocket connections work and how the
kubelet maps HTTP methods to RBAC verbs. The
WebSocket protocol (RFC 6455)
requires an HTTP GET request for the initial connection handshake. The kubelet
maps this GET to the RBAC get verb and authorizes the request without
performing a secondary check to confirm that CREATE permission is also present
for the write operation that follows. Using a WebSocket client like websocat,
an attacker can reach the kubelet's /exec endpoint directly on port 10250 and
execute arbitrary commands:
websocat --insecure \
--header "Authorization: Bearer $TOKEN" \
--protocol v4.channel.k8s.io \
"wss://$NODE_IP:10250/exec/default/nginx/nginx?output=1&error=1&command=id"
uid=0(root) gid=0(root) groups=0(root)
Fine-grained kubelet authorization: how it works
With KubeletFineGrainedAuthz, the kubelet now performs an additional, more
specific authorization check before falling back to the nodes/proxy
subresource. Several commonly used kubelet API paths are mapped to their own
dedicated subresources:
kubelet API
Resource
Subresource
/stats/*
nodes
stats
/metrics/*
nodes
metrics
/logs/*
nodes
log
/pods
nodes
pods, proxy
/runningPods/
nodes
pods, proxy
/healthz
nodes
healthz, proxy
/configz
nodes
configz, proxy
/spec/*
nodes
spec
/checkpoint/*
nodes
checkpoint
all others
nodes
proxy
For the endpoints that now have fine-grained subresources (/pods,
/runningPods/, /healthz, /configz), the kubelet first sends a
SubjectAccessReview for the specific subresource. If that check succeeds, the
request is authorized. If it fails, the kubelet retries with the coarse-grained
nodes/proxy subresource for backward compatibility.
This dual-check approach ensures a smooth migration path. Existing workloads
with nodes/proxy permissions continue to work, while new deployments can adopt
least-privilege access from day one.
What this means in practice
Consider a Prometheus node exporter or a monitoring DaemonSet that needs to
scrape /metrics from the kubelet. Previously, you would need an RBAC
ClusterRole like this:
# Old approach: overly broad
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: monitoring-agent
rules:
- apiGroups: [""]
resources: ["nodes/proxy"]
verbs: ["get"]
This grants the monitoring agent far more access than it needs. With fine-grained authorization, you can now scope the permissions precisely:
# New approach: least privilege
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: monitoring-agent
rules:
- apiGroups: [""]
resources: ["nodes/metrics", "nodes/stats"]
verbs: ["get"]
The monitoring agent can now read metrics and stats from the kubelet without
ever being able to execute commands in containers.
Updated system:kubelet-api-admin ClusterRole
When RBAC authorization is enabled, the built-in system:kubelet-api-admin
ClusterRole is automatically updated to include permissions for all the new
fine-grained subresources. This ensures that cluster administrators who already
use this role, including the API server's kubelet client, continue to have
full access without any manual configuration changes.
The role now includes permissions for:
nodes/proxynodes/statsnodes/metricsnodes/lognodes/specnodes/checkpointnodes/configznodes/healthznodes/pods
Upgrade considerations
Because the kubelet performs a dual authorization check (fine-grained first,
then falling back to nodes/proxy), upgrading to v1.36 should be seamless for
most clusters:
- Existing workloads with
nodes/proxypermissions continue to work without changes. The fallback tonodes/proxyensures backward compatibility. - The API server always has
nodes/proxypermissions viasystem:kubelet-api-admin, sokube-apiserver-to-kubeletcommunication is unaffected regardless of feature gate state. - Mixed-version clusters are handled gracefully. If a
kubeletsupports fine-grained authorization but the API server does not (or vice versa),nodes/proxypermissions serve as the fallback.
Verifying the feature is enabled
You can confirm that the feature is active on a given node by checking the
kubelet metrics endpoint. Since the metrics endpoint on port 10250 requires
authorization, you'll first need to create appropriate RBAC bindings for the pod
or ServiceAccount making the request.
Step 1: Create a ServiceAccount and ClusterRole
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubelet-metrics-checker
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kubelet-metrics-reader
rules:
- apiGroups: [""]
resources: ["nodes/metrics"]
verbs: ["get"]
Step 2: Bind the ClusterRole to the ServiceAccount
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubelet-metrics-checker
subjects:
- kind: ServiceAccount
name: kubelet-metrics-checker
namespace: default
roleRef:
kind: ClusterRole
name: kubelet-metrics-reader
apiGroup: rbac.authorization.k8s.io
Apply both manifests:
kubectl apply -f serviceaccount.yaml
kubectl apply -f clusterrole.yaml
kubectl apply -f clusterrolebinding.yaml
Step 3: Run a pod with the ServiceAccount and check the feature flag
kubectl run kubelet-check \
--image=curlimages/curl \
--serviceaccount=kubelet-metrics-checker \
--restart=Never \
--rm -it \
-- sh
Then from within the pod, retrieve the node IP and query the metrics endpoint:
# Get the token
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
# Query the kubelet metrics and filter for the feature gate
curl -sk \
--header "Authorization: Bearer $TOKEN" \
https://$NODE_IP:10250/metrics \
| grep kubernetes_feature_enabled \
| grep KubeletFineGrainedAuthz
If the feature is enabled, you should see output like:
kubernetes_feature_enabled{name="KubeletFineGrainedAuthz",stage="GA"} 1
Note: Replace
$NODE_IPwith the IP address of the node you want to check. You can retrieve node IPs withkubectl get nodes -o wide.
The journey from alpha to GA
Release Stage Details v1.32 Alpha Feature gateKubeletFineGrainedAuthz introduced, disabled by default
v1.33
Beta
Enabled by default; fine-grained checks for /pods, /runningPods/, /healthz, /configz
v1.36
GA
Feature gate locked to enabled; fine-grained kubelet authorization is always active
What's next?
With fine-grained kubelet authorization now GA, the Kubernetes community can
begin recommending and eventually enforcing the use of specific subresources
instead of nodes/proxy for monitoring and observability workloads. The urgency
of this migration is underscored by
research showing that nodes/proxy GET can be abused for unlogged remote code execution via the WebSocket protocol. This risk is present in the default RBAC
configurations of dozens of widely deployed Helm charts. Over time, we expect:
- Ecosystem adoption: Monitoring tools like Prometheus, Datadog agents, and
other
DaemonSetscan update their default RBAC configurations to usenodes/metrics,nodes/stats, andnodes/podsinstead ofnodes/proxy. This directly eliminates the WebSocket RCE attack surface for those workloads. - Policy enforcement: Admission controllers and policy engines can flag or
reject RBAC bindings that grant
nodes/proxywhen fine-grained alternatives exist, helping organizations adopt least-privilege access at scale. - Deprecation path: As adoption grows,
nodes/proxymay eventually be deprecated for monitoring use cases, further reducing the attack surface of Kubernetes clusters.
Getting involved
This enhancement was driven by SIG Auth and SIG Node. If you are interested in contributing to the security and authorization features of Kubernetes, please join us:
- SIG Auth
- SIG Node
- Slack:
#sig-authand#sig-node - KEP-2862: Fine-Grained Kubelet API Authorization
We look forward to hearing your feedback and experiences with this feature!
Kubernetes v1.36: Fine-Grained Kubelet API Authorization Graduates to GA
On behalf of Kubernetes SIG Auth and SIG Node, we are pleased to announce the
graduation of fine-grained kubelet API authorization to General Availability
(GA) in Kubernetes v1.36!
The KubeletFineGrainedAuthz feature gate was introduced as an opt-in alpha
feature in Kubernetes v1.32, then graduated to beta (enabled by default) in
v1.33. Now, the feature is generally available and the feature gate is locked
to enabled. This feature enables more precise, least-privilege access control
over the kubelet's HTTPS API, replacing the need to grant the overly broad
nodes/proxy permission for common monitoring and observability use cases.
Motivation: the nodes/proxy problem
The kubelet exposes an HTTPS endpoint with several APIs that give access to data
of varying sensitivity, including pod listings, node metrics, container logs,
and, critically, the ability to execute commands inside running containers.
Prior to this feature, kubelet authorization used a coarse-grained model. When
webhook authorization was enabled, almost all kubelet API paths were mapped to a
single nodes/proxy subresource. This meant that any workload needing to read
metrics or health status from the kubelet required nodes/proxy permission,
the same permission that also grants the ability to execute arbitrary commands
in any container running on the node.
What's wrong with that?
Granting nodes/proxy to monitoring agents, log collectors, or health-checking
tools violates the principle of least privilege. If any of those workloads were
compromised, an attacker would gain the ability to run commands in every
container on the node. The nodes/proxy permission is effectively a node-level
superuser capability, and granting it broadly dramatically increases the blast
radius of a security incident.
This problem has been well understood in the community for years (see kubernetes/kubernetes#83465), and was the driving motivation behind this enhancement KEP-2862.
The nodes/proxy GET WebSocket RCE risk
The situation is more severe than it might appear at first glance. Security
researchers demonstrated in early 2026
that nodes/proxy GET alone, which is the minimal read-only permission routinely
granted to monitoring tools, can be abused to execute commands in any pod on
reachable nodes.
The root cause is a mismatch between how WebSocket connections work and how the
kubelet maps HTTP methods to RBAC verbs. The
WebSocket protocol (RFC 6455)
requires an HTTP GET request for the initial connection handshake. The kubelet
maps this GET to the RBAC get verb and authorizes the request without
performing a secondary check to confirm that CREATE permission is also present
for the write operation that follows. Using a WebSocket client like websocat,
an attacker can reach the kubelet's /exec endpoint directly on port 10250 and
execute arbitrary commands:
websocat --insecure \
--header "Authorization: Bearer $TOKEN" \
--protocol v4.channel.k8s.io \
"wss://$NODE_IP:10250/exec/default/nginx/nginx?output=1&error=1&command=id"
uid=0(root) gid=0(root) groups=0(root)
Fine-grained kubelet authorization: how it works
With KubeletFineGrainedAuthz, the kubelet now performs an additional, more
specific authorization check before falling back to the nodes/proxy
subresource. Several commonly used kubelet API paths are mapped to their own
dedicated subresources:
kubelet API
Resource
Subresource
/stats/*
nodes
stats
/metrics/*
nodes
metrics
/logs/*
nodes
log
/pods
nodes
pods, proxy
/runningPods/
nodes
pods, proxy
/healthz
nodes
healthz, proxy
/configz
nodes
configz, proxy
/spec/*
nodes
spec
/checkpoint/*
nodes
checkpoint
all others
nodes
proxy
For the endpoints that now have fine-grained subresources (/pods,
/runningPods/, /healthz, /configz), the kubelet first sends a
SubjectAccessReview for the specific subresource. If that check succeeds, the
request is authorized. If it fails, the kubelet retries with the coarse-grained
nodes/proxy subresource for backward compatibility.
This dual-check approach ensures a smooth migration path. Existing workloads
with nodes/proxy permissions continue to work, while new deployments can adopt
least-privilege access from day one.
What this means in practice
Consider a Prometheus node exporter or a monitoring DaemonSet that needs to
scrape /metrics from the kubelet. Previously, you would need an RBAC
ClusterRole like this:
# Old approach: overly broad
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: monitoring-agent
rules:
- apiGroups: [""]
resources: ["nodes/proxy"]
verbs: ["get"]
This grants the monitoring agent far more access than it needs. With fine-grained authorization, you can now scope the permissions precisely:
# New approach: least privilege
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: monitoring-agent
rules:
- apiGroups: [""]
resources: ["nodes/metrics", "nodes/stats"]
verbs: ["get"]
The monitoring agent can now read metrics and stats from the kubelet without
ever being able to execute commands in containers.
Updated system:kubelet-api-admin ClusterRole
When RBAC authorization is enabled, the built-in system:kubelet-api-admin
ClusterRole is automatically updated to include permissions for all the new
fine-grained subresources. This ensures that cluster administrators who already
use this role, including the API server's kubelet client, continue to have
full access without any manual configuration changes.
The role now includes permissions for:
nodes/proxynodes/statsnodes/metricsnodes/lognodes/specnodes/checkpointnodes/configznodes/healthznodes/pods
Upgrade considerations
Because the kubelet performs a dual authorization check (fine-grained first,
then falling back to nodes/proxy), upgrading to v1.36 should be seamless for
most clusters:
- Existing workloads with
nodes/proxypermissions continue to work without changes. The fallback tonodes/proxyensures backward compatibility. - The API server always has
nodes/proxypermissions viasystem:kubelet-api-admin, sokube-apiserver-to-kubeletcommunication is unaffected regardless of feature gate state. - Mixed-version clusters are handled gracefully. If a
kubeletsupports fine-grained authorization but the API server does not (or vice versa),nodes/proxypermissions serve as the fallback.
Verifying the feature is enabled
You can confirm that the feature is active on a given node by checking the
kubelet metrics endpoint. Since the metrics endpoint on port 10250 requires
authorization, you'll first need to create appropriate RBAC bindings for the pod
or ServiceAccount making the request.
Step 1: Create a ServiceAccount and ClusterRole
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubelet-metrics-checker
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kubelet-metrics-reader
rules:
- apiGroups: [""]
resources: ["nodes/metrics"]
verbs: ["get"]
Step 2: Bind the ClusterRole to the ServiceAccount
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubelet-metrics-checker
subjects:
- kind: ServiceAccount
name: kubelet-metrics-checker
namespace: default
roleRef:
kind: ClusterRole
name: kubelet-metrics-reader
apiGroup: rbac.authorization.k8s.io
Apply both manifests:
kubectl apply -f serviceaccount.yaml
kubectl apply -f clusterrole.yaml
kubectl apply -f clusterrolebinding.yaml
Step 3: Run a pod with the ServiceAccount and check the feature flag
kubectl run kubelet-check \
--image=curlimages/curl \
--serviceaccount=kubelet-metrics-checker \
--restart=Never \
--rm -it \
-- sh
Then from within the pod, retrieve the node IP and query the metrics endpoint:
# Get the token
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
# Query the kubelet metrics and filter for the feature gate
curl -sk \
--header "Authorization: Bearer $TOKEN" \
https://$NODE_IP:10250/metrics \
| grep kubernetes_feature_enabled \
| grep KubeletFineGrainedAuthz
If the feature is enabled, you should see output like:
kubernetes_feature_enabled{name="KubeletFineGrainedAuthz",stage="GA"} 1
Note: Replace
$NODE_IPwith the IP address of the node you want to check. You can retrieve node IPs withkubectl get nodes -o wide.
The journey from alpha to GA
Release Stage Details v1.32 Alpha Feature gateKubeletFineGrainedAuthz introduced, disabled by default
v1.33
Beta
Enabled by default; fine-grained checks for /pods, /runningPods/, /healthz, /configz
v1.36
GA
Feature gate locked to enabled; fine-grained kubelet authorization is always active
What's next?
With fine-grained kubelet authorization now GA, the Kubernetes community can
begin recommending and eventually enforcing the use of specific subresources
instead of nodes/proxy for monitoring and observability workloads. The urgency
of this migration is underscored by
research showing that nodes/proxy GET can be abused for unlogged remote code execution via the WebSocket protocol. This risk is present in the default RBAC
configurations of dozens of widely deployed Helm charts. Over time, we expect:
- Ecosystem adoption: Monitoring tools like Prometheus, Datadog agents, and
other
DaemonSetscan update their default RBAC configurations to usenodes/metrics,nodes/stats, andnodes/podsinstead ofnodes/proxy. This directly eliminates the WebSocket RCE attack surface for those workloads. - Policy enforcement: Admission controllers and policy engines can flag or
reject RBAC bindings that grant
nodes/proxywhen fine-grained alternatives exist, helping organizations adopt least-privilege access at scale. - Deprecation path: As adoption grows,
nodes/proxymay eventually be deprecated for monitoring use cases, further reducing the attack surface of Kubernetes clusters.
Getting involved
This enhancement was driven by SIG Auth and SIG Node. If you are interested in contributing to the security and authorization features of Kubernetes, please join us:
- SIG Auth
- SIG Node
- Slack:
#sig-authand#sig-node - KEP-2862: Fine-Grained Kubelet API Authorization
We look forward to hearing your feedback and experiences with this feature!