Feed aggregator
Sen. Wyden Warns of Another Section 702 Abuse
Sen. Ron Wyden is warning us of an abuse of Section 702:
Wyden took to the Senate floor to deliver a lengthy speech, ostensibly about the since approved (with support of many Democrats) nomination of Joshua Rudd to lead the NSA. Wyden was protesting that nomination, but in the context of Rudd being unwilling to agree to basic constitutional limitations on NSA surveillance. But that’s just a jumping off point ahead of Section 702’s upcoming reauthorization deadline. Buried in the speech is a passage that should set off every alarm bell:
There’s another example of secret law related to Section 702, one that directly affects the privacy rights of Americans. For years, I have asked various administrations to declassify this matter. Thus far they have all refused, although I am still waiting for a response from DNI Gabbard. I strongly believe that this matter can and should be declassified and that Congress needs to debate it openly before Section 702 is reauthorized. In fact, ...
Istio Brings Future Ready Service Mesh to the AI Era with New Ambient Multicluster, Gateway API Inference Extension and More
New beta capabilities and experimental support aim to simplify service mesh adoption while expanding Istio’s role in next-generation AI infrastructure
Key Highlights:
- Istio announced ambient multicluster beta, Gateway API Inference Extension beta and experimental agentgateway support at KubeCon + CloudNativeCon Europe 2026.
- New updates simplify multicluster operations and introduce optimized model routing to support AI inference on Kubernetes.
- Updates from Istio benefit platform engineers, operators and application teams running distributed and AI workloads.
KUBECON + CLOUDNATIVECON EUROPE, AMSTERDAM—25 MARCH, 2025—The Cloud Native Computing Foundation® (CNCF®), which builds sustainable ecosystems for cloud native software, today announced that Istio has launched a host of new features designed to meet the rising needs of modern, AI-driven infrastructure while reducing operational complexity. Updates include the beta release of ambient multicluster support, a beta release of Gateway API Inference Extension and experimental support for agentgateway as a component of the Istio data plane.
CNCF’s Annual Cloud Native Survey found that 66% of organizations are running GenAI workloads on Kubernetes, yet only 7% achieve daily deployments for AI workloads. The data also shows that innovators are nearly three times more likely than explorers to run service mesh in production, signaling that maturity in cloud native practices correlates with advanced traffic management and security adoption.
As AI inference models increasingly run on Kubernetes clusters, projects such as Istio are valuable in securing, routing and observing that traffic. New beta features, such as the simplified Ambient Multicluster, are designed to eliminate the complexity that often impedes organizations from reaching daily deployment velocity for these critical AI workloads. These updates reflect a broader shift toward platform engineering teams building guardrails and infrastructure needed to safely operate the rising demands of AI workloads.
“After nine years, Istio continues to evolve to meet users where they are and where they’re headed,” said Chris Aniszczyk, CTO, CNCF. “These new updates signal Istio’s commitment to being the service mesh of the future for agentic workloads and more.”
Istio’s latest updates are designed to meet the rising demands of AI workloads and simplify operations for all users. Key features include:
- Ambient Multicluster (beta): Ambient Multicluster extends Istio’s ambient mode to support traffic routing across multiple clusters without sidecars, simplifying the deployment and management of service mesh. The result is a simplified approach for teams running applications across regions or clouds for scale and resilience.
- Gateway API Inference Extension (beta): Built as an enhancement to the Gateway API, the extension integrates machine learning inference directly into mesh traffic flows, offering a consistent developer experience (DevEx) that streamlines operations for platform teams familiar with the Kubernetes standard.
- Agentgateway: Experimental support for agentgateway: Experimental support for agentgateway, as part of the Istio data plane, reflects the community’s focus on exploring more flexible, lightweight traffic handling to keep pace with AI development. Originally created by Solo.io and now a Linux Foundation project, agentgateway is designed to help manage dynamic AI-driven traffic patterns. Through this experimental integration, Istio aims to provide a foundation for emerging AI use cases while maintaining compatibility with existing service mesh deployments.
“Istio’s evolution reflects where cloud native infrastructure is headed,” said Keith Mattix, Istio maintainer. “Users want simpler multicluster operations and they want to run AI workloads with confidence. These releases deliver both while staying true to Istio’s roots.”
Together, these updates position Istio to support a shift already underway in cloud native environments. As AI workloads increasingly run on Kubernetes, service mesh technologies like Istio provide the networking, security and observability needed to manage that traffic at scale, supporting everything from model training and inference to agentic systems.
Learn more about Istio and join the community: https://istio.io/
About Cloud Native Computing Foundation
Cloud native computing empowers organizations to build and run scalable applications with an open source software stack in public, private, and hybrid clouds. The Cloud Native Computing Foundation (CNCF) hosts critical components of the global technology infrastructure, including Kubernetes, Prometheus, and Envoy. CNCF brings together the industry’s top developers, end users, and vendors and runs the largest open source developer conferences in the world. Supported by nearly 800 members, including the world’s largest cloud computing and software companies, as well as over 200 innovative startups, CNCF is part of the nonprofit Linux Foundation. For more information, please visit www.cncf.io.
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our trademark usage page. Linux is a registered trademark of Linus Torvalds.
Media Contact
Haley White
The Linux Foundation
Announcing the release of KubeVirt v1.8
The KubeVirt Community is happy to announce the release of v1.8, which aligns with Kubernetes v1.35.
This is the third release since we started our VEP (Virt Enhancement Proposal) process and, after some shaky starts and concerted iterating, we are really starting to see it settle and find a rhythm in the community. We have had a real boom in proposals for this release, and that trend is likely to continue. It’s wonderful to see new contributors coming forward with exciting ideas and engage with the project to see them through.
You can read the full release notes in our user-guide, but we have included some highlights in this blog.
For those of you at KubeCon this week, we have a whole bunch of talks, as well as a project kiosk, which we have listed on our events wiki.
We are also running our first in-person event: KubeVirt Summit Live at the Cloud Native Theatre on Thursday March 26th.
### SIG Compute
The Confidential Computing Working Group has introduced improvements to support Intel TDX Attestation in KubeVirt; confidential VMs can now certify that they are running on confidential hardware (Intel TDX currently).
Another major milestone is the introduction of Hypervisor Abstraction Layer, which enables KubeVirt to integrate multiple hypervisor backends beyond KVM, while still maintaining the current KVM-first behaviour as default.
And because good things happen in threes, we’ve also enabled AI and HPC workloads in VMs to achieve near-native performance with the introduction of PCIe NUMA topology awareness alongside other resource improvements.
### SIG Networking
The `passt` binding has been promoted from a plugin to a core binding. This binding is a significant improvement to an earlier implementation.
Also, you can now live update NAD references without requiring VM restart, allowing you to change a VM’s backing network without disrupting the guest.
And we have decoupled KubeVirt from NAD definitions to reduce API calls made by virt-controller, removing a performance bottleneck for VM activation at scale and improving security by removing permissions. Users should be aware that this is a deprecating process and prepare accordingly.
### SIG Storage
The big news on the storage front is two new features: ContainerPath volume and Incremental Backup with CBT.
ContainerPath volumes allow you to map container paths for VM storage and improve portability and configuration options. This provides an escape hatch for cloud provider credential injection patterns.
Incremental Backup with Changed Block Tracking (CBT) leverages QEMU’s and libvirt backup capabilities providing storage agnostic incremental VM backups. By capturing only modified data, the solution eliminates reliance on specific CSI drivers, allowing for faster backup windows and a drastically reduced storage footprint. This not only ensures storage freedom but also minimizes cluster network traffic for peak efficiency.
### SIG Scale and Performance
There have been a few test improvements rolled out in SIG Scale and Performance. First, we have increased the KWOK performance test to 8000 VMIs. The results have shown the kubevirt control-plane performs well even as VMI counts grow. On the scale side, when comparing the 100 VMI job to 8000 VMI job, we see some expected memory increases. The average virt-api memory grows from 140MB to 170MB (+30MB) and average virt-controller memory grows from 65MB to 1400MB (+1335MB).
To determine the memory scaling per Virtual Machine Instance (VMI), we calculate the rate of change on the control-plane in the 100 real VMIs and 8000 KWOK VMIs. This estimates the incremental memory cost for each additional VMI added to the system.
ComponentTotal Memory Increase 100 to 8000 (Δ)Memory Scale per VMI (MB)Memory Scale per VMI (KB)virt-api30 MB0.0038 MB3.89 KBvirt-controller1335 MB0.1690 MB173.04 KBWe will continue to refine these measurements as they are still estimates and may have some incorrect measurements. Our goal is to eventually publish this along this our comprehensive list of performance and scale benchmarks for each release, which is here.
### Thanks!
A lot of work from a huge amount of people go into these releases. Some contributions are small, such as raising a bug or attending our community meeting, and others are massive, like working on a feature or reviewing PRs. Whatever your part: we thank you.
We had a huge amount of features and the next release is looking to be larger still. If you’re interested in contributing and being a part of this great project, please check out our contributing guide and our community membership guidelines. Reviewing PRs is a great way to learn and gain experience, but it can sometimes be daunting. If you’d like to be involved but aren’t sure, reach out on our Slack or mailing list; we have some wonderful people in the community who can help you find your feet.
Team Mirai and Democracy
Japan’s election last month and the rise of the country’s newest and most innovative political party, Team Mirai, illustrates the viability of a different way to do politics.
In this model, technology is used to make democratic processes stronger, instead of undermining them. It is harnessed to root out corruption, instead of serving as a cash cow for campaign donations.
Imagine an election where every voter has the opportunity to opine directly to politicians on precisely the issues they care about. They’re not expected to spend hours becoming policy experts. Instead, an ...
Tekton Becomes a CNCF Incubating Project
The CNCF Technical Oversight Committee (TOC) has voted to accept Tekton as a CNCF incubating project.
What is Tekton?
Tekton is a powerful and flexible open source framework for creating continuous integration and delivery (CI/CD) systems that allows developers to build, test, and deploy across multiple cloud providers and on-premises systems by abstracting away the underlying implementation details.
While widely adopted for CI/CD, Tekton serves as a general-purpose, security-minded, Kubernetes-native workflow engine. Its composable primitives (Steps, Tasks and Pipelines) allow developers to orchestrate any type of sequential or parallel workload on Kubernetes. Tekton provides a standard, Kubernetes-native interface for defining these workflows, making them portable and reusable.
Tekton’s Key Milestones
The project has matured into a leading framework for Kubernetes-native CI/CD, reaching its stable v1.0 release for the core Pipelines component.
By joining the CNCF, Tekton aligns itself more closely with the ecosystem it powers. It integrates deeply with other CNCF projects like Argo CD (for GitOps) and SPIFFE/SPIRE (for identity), and also Sigstore via OpenSSF (for signing and verification), creating a robust supply chain security story.
Tekton is widely adopted in the industry and used by companies like Puppet and Ford Motor Company. Additionally, Tekton powers major commercial CI/CD offerings, including, but not limited to: Red Hat OpenShift Pipelines and IBM Cloud Continuous Delivery.
A Message from the Tekton Team
“One of the accomplishments I’m most proud of is the broad adoption of Tekton across open source projects, commercial products, and in-house platforms. Seeing teams rely on it in production and build on it within their own ecosystems has been especially rewarding. As a Kubernetes-native project that integrates naturally with other CNCF technologies, Tekton has benefited from close collaboration within the Cloud Native Computing Foundation community. I’m looking forward to deepening those partnerships, learning from our peers across CNCF projects, and meeting more Tekton users who are shaping what cloud native delivery looks like in practice.”
— Andrea Frittoli, Tekton Governing Board Member
“What I’m most proud of is how Tekton has shown that CI/CD can be a true Kubernetes-native primitive, not just another layer on top. Seeing projects like Shipwright—itself a CNCF project—and Konflux build on Tekton as their foundation validates that vision. Building all of this alongside a diverse, multi-vendor community with Red Hat, Google, IBM, and many individual contributors has been one of the most rewarding open source experiences of my career. I’m looking forward to what comes next. The future of Tekton is Trusted Artifacts changing how tasks share data, a simpler developer experience through Pipelines as Code, and deeper collaboration with CNCF projects like Sigstore and Argo CD. Tekton is fundamentally a Kubernetes project, and CNCF is its natural home.”
— Vincent Demeester, Tekton Governing Board Member
Support from TOC Sponsors
The CNCF Technical Oversight Committee (TOC) provides technical leadership to the cloud native community. It defines and maintains the foundation’s technical vision, approves new projects, and stewards them across maturity levels. The TOC also aligns projects within the overall ecosystem, sets cross-cutting standards and best practices and works with end users to ensure long-term sustainability. As part of its charter, the TOC evaluates and supports projects as they meet the requirements for incubation and continue progressing toward graduation.
“Tekton has proven itself as core infrastructure for Kubernetes-native delivery. Its move to incubation reflects strong multi-vendor governance and deep alignment with CNCF projects focused on GitOps, identity and software supply chain security.”
— Chad Beaudin, TOC Sponsor, Cloud Native Computing Foundation
“Tekton’s composable design and broad adoption make it an important part of the cloud native workflow landscape. The TOC’s vote recognizes a healthy contributor community and a clear roadmap.”
— Jeremy Rickard, TOC Sponsor, Cloud Native Computing Foundation
The Main Components of Tekton
- Pipelines: The core building blocks (Tasks, Pipelines, Workspaces) for defining CI/CD workflows.
- Triggers: Allows pipelines to be instantiated based on events (like Git pushes or pull requests).
- CLI: A command-line interface for interacting with Tekton resources.
- Dashboard: A web-based UI for visualizing and managing pipelines.
- Chains: A supply chain security tool that automatically signs and attests artifacts built by Tekton.
Community Highlights
These community metrics signal strong momentum and healthy open source governance. For a CNCF project, this level of engagement builds trust with adopters, ensures long-term sustainability and reflects the collaborative innovation that defines the cloud native ecosystem. Tekton’s notable milestones include:
- 11,000+ GitHub Stars (across all repositories)
- 5,000+ Pull Requests
- 2,500+ Issues
- 600+ Contributors
- 1.0 Stable Release of Pipelines
The Future of Tekton
The Tekton roadmap focuses on stability, security and scalability. Key initiatives from the project board and enhancement proposals (TEPs) include:
- Supply Chain Security: Enhancing Tekton Chains to meet SLSA Level 3 requirements by default, including better provenance for build artifacts.
- Trusted Artifacts: Introducing a secure and efficient way to pass data between tasks without relying on shared storage (PVCs), significantly improving performance and isolation (TEP-0139).
- Concise Syntax: Exploring less verbose syntax for referencing remote tasks and pipelines to improve developer experience (TEP-0154).
- Advanced Scheduling: Integrating with Kueue for better job queuing and priority management of PipelineRuns.
- Tekton Results: Moving the Results API to stable to provide long-term history and query capabilities for PipelineRuns and TaskRuns.
- Catalog Evolution: Transitioning reusable tasks to Artifact Hub for better discoverability and standardized distribution.
- Pipelines as Code: Continued investment in Git-based workflows, improving the “as code” experience for defining and managing pipelines.
For more details, see the Tekton Project Board and approved TEPs (Tekton Enhancement Proposals).
As a CNCF-hosted project, Tekton is committed to the principles of open source, neutrality and collaboration. We invite global developers and ecosystem partners to join us in enabling data to flow and be efficiently used freely anywhere, anytime. For more information on maturity requirements for each level, please visit the CNCF Graduation Criteria.
Fluid Becomes a CNCF Incubating Project
The CNCF Technical Oversight Committee (TOC) has voted to accept Fluid as a CNCF incubating project.
What is Fluid?
Kubernetes provides a data access layer through the Container Storage Interface (CSI), enabling workloads to connect to storage systems. However, certain use cases often require additional capabilities such as dataset versioning, access controls, preprocessing, dynamic mounting, and data acceleration.
To help address these needs, Nanjing University, Alibaba Cloud, and the Alluxio community introduced Fluid, a cloud native data orchestration and acceleration system that treats “elastic datasets” as a first-class resource. By adding a data abstraction layer within Kubernetes environments, Fluid enhances data flow and management for data-intensive workloads.
Fluid’s vision is Data Anyway, Anywhere, Anytime:
- Anyway: Fluid focuses on data accessibility. Storage vendors can flexibly and simply integrate various storage clients without needing deep or extensive knowledge of Kubernetes CSI or Golang programming.
- Anywhere: Fluid facilitates efficient data access across diverse infrastructure by supporting heterogeneous computing environments (cloud, edge, and serverless). It accelerates access to various storage systems like HDFS, S3, GCS, and CubeFS by utilizing caching engines such as Alluxio, JuiceFS, and Vineyard.
- Anytime: Runtime dynamic adjustment of data sources allows data scientists to add and remove storage data sources on-demand in Kubernetes environments without service interruption.
Fluid’s Key Milestones and Ecosystem Development
Fluid originated as a joint project from Nanjing University, Alibaba Cloud, and the Alluxio community in September 2020. The project aims to provide efficient, elastic, and transparent data access capabilities for data-intensive AI applications in cloud native environments. In May 2021, Fluid was officially accepted as a CNCF sandbox project.
Since joining the CNCF, Fluid has rapidly grown, continuously releasing multiple important updates, achieving significant breakthroughs in key capabilities such as elastic data cache scaling, unified access to heterogeneous data sources, and application-transparent scheduling, while also improving the operational efficiency of AI and big data workloads on cloud native platforms.
Fluid’s core design concepts and technological innovations have received high-level academic recognition, with related results published in top conferences and journals in the database and computer systems fields, such as IEEE TPDS 2023.
In December 2024, at KubeCon + CloudNativeCon North America, CNCF released the 2024 Technology Landscape Radar Report, where Fluid, along with projects such as Kubeflow, was listed as “Adopt,”becoming one of the de facto standards in the cloud native AI and big data field.
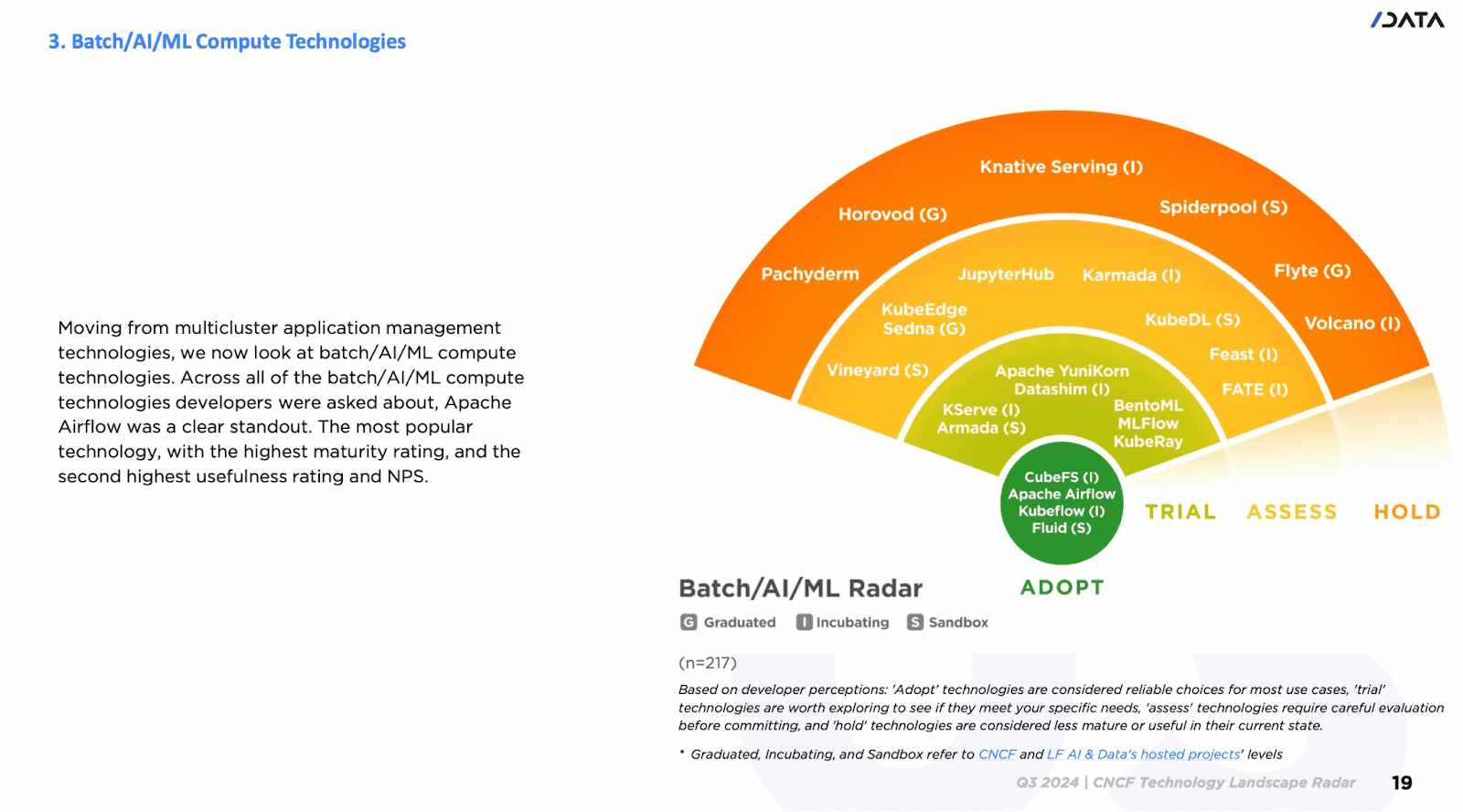
Now, Fluid has been widely adopted across multiple industries and regions worldwide, with users covering major cloud service providers, internet companies, and vertical technology companies. Some Fluid users include Xiaomi, Alibaba Group, NetEase, China Telecom, Horizon, Weibo, Bilibili, 360, Zuoyebang, Inceptio Technology, Huya, OPPO, Unisound, DP Technology, JoinQuant, among others. Use cases cover a wide range of application scenarios, including, but not limited to, Artificial Intelligence Generated Content (AIGC), large models, big data, hybrid cloud, cloud-based development machine management, and autonomous driving data simulation.
A Word from the Maintainers
“We are deeply honored to see Fluid promoted to an incubating project. Our original intention in initiating Fluid was to fill the gap between compute and storage in cloud native architectures, allowing data to flow freely in the cloud like ‘fluid.’ The vibrant community development and widespread user adoption validate our vision. We will continue to drive the evolution of cloud native data orchestration technology, especially when it comes to exploring intelligent scheduling and orchestration of KVCache for large model inference scenarios and dedicating ourselves to making data serve various applications more efficiently and intelligently.”
— Gu Rong (Nanjing University), Chair and Co-Founder of the Fluid Community
“From sandbox to incubation, the concept of ‘caches also needing elasticity’ has gained widespread recognition. In the future, we will continue to drive Fluid toward becoming the standard for cloud native data orchestration, allowing data scientists to focus on model innovation.”
— Che Yang (Alibaba Cloud), Fluid Community Maintainer and Co-Founder
“Fluid is a key bridge to connecting AI computing frameworks and distributed storage systems. Seeing Fluid grow from a sandbox to an incubating project makes us extremely proud. This milestone proves that building a standardized data abstraction layer on Kubernetes is keeping up with industry trends.”
— Fan Bin (Alluxio Inc.), Alluxio Open Source Community Maintainer
Support from TOC Sponsors
The TOC provides technical leadership to the cloud native community. It defines and maintains the foundation’s technical vision, approves new projects, and stewards them across maturity levels. The TOC also aligns projects within the overall ecosystem, sets cross-cutting standards and best practices, and works with end users to ensure long-term sustainability. As part of its charter, the TOC evaluates and supports projects as they meet the requirements for incubation and continue progressing toward graduation.
“Fluid’s progression to incubation reflects both its technical maturity and the clear demand we’re seeing for stronger data orchestration in cloud native environments. As AI and data-intensive workloads continue to grow on Kubernetes, projects like Fluid help bridge compute and storage in a way that is practical, scalable, and community-driven. The TOC looks forward to supporting the project’s continued evolution within the CNCF ecosystem.”
— Alex Chircop, CNCF TOC Member
“Fluid has demonstrated a strong level of maturity that aligns well with CNCF Incubation expectations. Adopter interviews showcase that Fluid has been deployed successfully in large-scale production environments for several years and provides standardized APIs that enable multiple applications to efficiently access and cache diverse datasets. Additionally, Fluid benefits from a healthy, engaged community, with a roadmap clearly shaped by adopter feedback.”
— Katie Gamanji, CNCF TOC Member
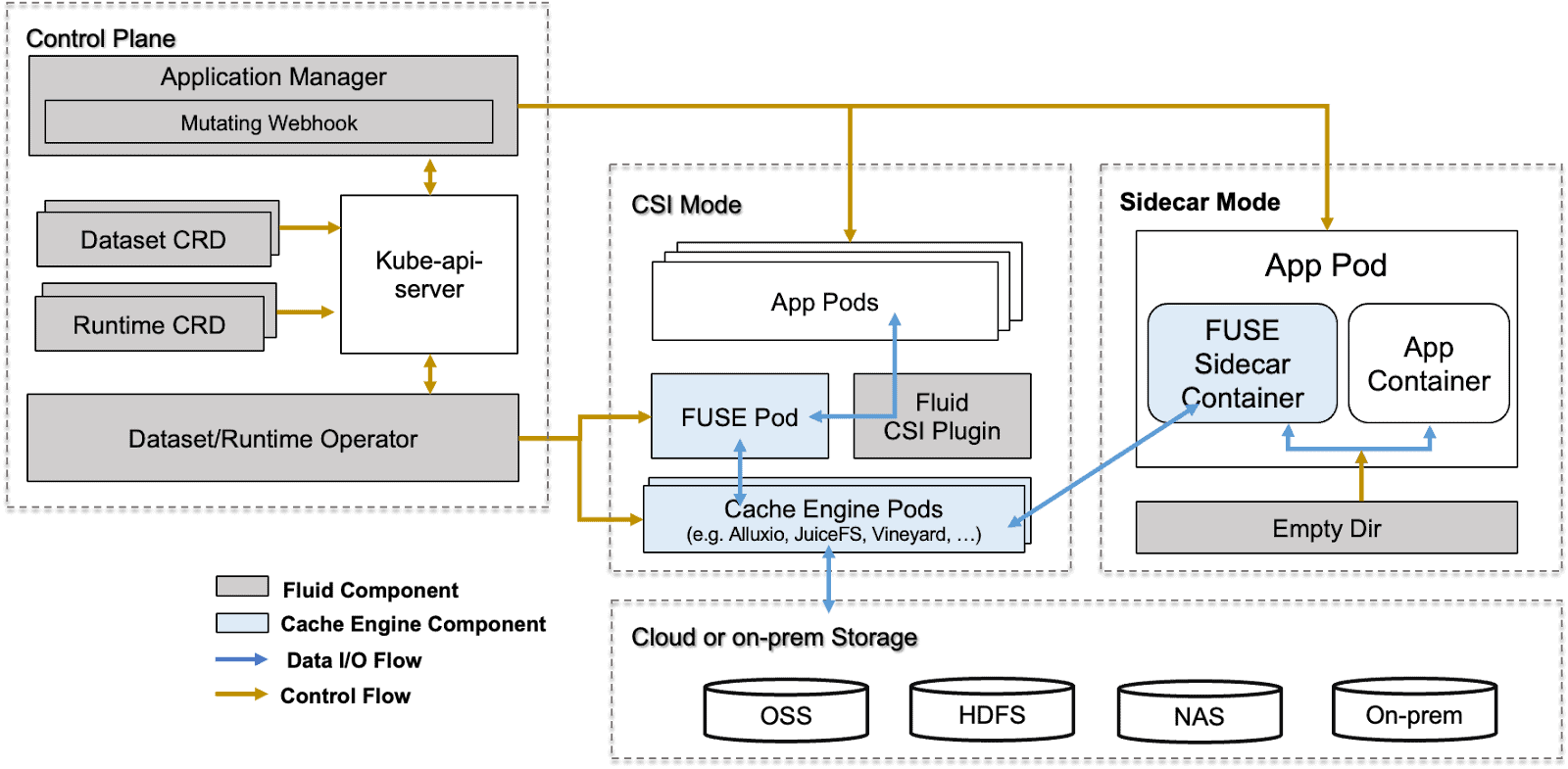
Main Components in Fluid
- Dataset Controller: Responsible for dataset abstraction and management, maintaining the binding relationship and status between data and underlying storage.
- Application Scheduler: The application scheduling component is responsible for perceiving data cache location information and scheduling application pods to the most suitable nodes.
- Runtime Plugins: Pluggable runtime interface responsible for deployment, configuration, scaling, and failure recovery of specific caching engines (such as Alluxio, JuiceFS, Vineyard, etc.), with excellent extensibility.
- Webhook: Utilizes the Mutating Admission Webhook mechanism to automatically inject sidecar or volume mount information into application pods, achieving zero intrusion into applications.
- CSI Plugin: Enables lightweight, transparent dataset mounting support for application pods, enabling them to access cached or remote data via local file system paths.
Community Highlights
These community metrics signal strong momentum and healthy open source governance. For a CNCF project, this level of engagement builds trust with adopters, ensures long-term sustainability, and reflects the collaborative innovation that defines the cloud native ecosystem.
- 1.9k GitHub Stars
- 116 pull requests
- 250 issues
- 979 contributors
- 28 Releases
The Journey Continues
Becoming a CNCF incubating project is a turning point for Fluid’s journey. Fluid will continue to deepen its data orchestration capabilities for generative AI and big data scenarios. To meet the exponential growth demands of GenAI applications, Fluid’s next goal is to evolve into an intelligent elastic data platform, allowing users to focus on model innovation and data value mining, while Fluid handles the underlying data distribution, cache acceleration, resource management, and elastic scaling.
As a CNCF incubating project, Fluid will continue to uphold the principles of open source, neutrality, and collaboration, working together with global developers and ecosystem partners to enable data to flow and be efficiently used freely anywhere, anytime.
Hear from Users
“Fluid’s Anytime capability allows our data scientists to self-service data switching without restarting Pods, truly achieving data agility. This is the core reason we chose Fluid over a self-built solution.”
— Liu Bin, Technical Lead at DP Technology
“Fluid’s vendor neutrality and cross-namespace cache sharing capabilities help us avoid cloud vendor lock-in and save approximately 40% in cross-cloud bandwidth costs. It has been deeply integrated into all of our data workflows.”
— Zhao Ming, Head of Horizon AI Platform
“In LLM model inference, remote Safetensors file reading often leads to low I/O utilization. Fluid’s intelligent prefetching and local caching technology allows us to fully saturate bandwidth without modifying code, fully unleashing GPU computing power.”
— Zhang Xiang, Head of NetEase MaaS
As a CNCF-hosted project, Fluid is committed to the principles of open source, neutrality and collaboration. We invite global developers and ecosystem partners to join us in enabling data to flow and be efficiently used freely anywhere, anytime. For more information on maturity requirements for each level, please visit the CNCF Graduation Criteria.
Cloud Native Computing Foundation Announces Kyverno’s Graduation
Kyverno reaches graduation after demonstrating broad enterprise adoption as platform teams adopt declarative governance
Key Highlights:
- Kyverno graduates from the Cloud Native Computing Foundation after demonstrating production readiness and strong adoption.
- Kyverno’s declarative policy-as-code solution makes it easier for platform and security teams to define and enforce guardrails across Kubernetes and cloud native environments.
- Since joining CNCF in 2020, the Kyverno community has grown significantly, expanding from 574 GitHub stars to more than 9,000 and attracting contributors and end users worldwide.
KUBECON + CLOUDNATIVECON NORTH EUROPE, AMSTERDAM, The Netherlands – March 24, 2026 – The Cloud Native Computing Foundation® (CNCF®), which builds sustainable ecosystems for cloud native software, today announced the graduation of Kyverno, a Kubernetes-native policy engine that enables organizations to define, manage and enforce policy-as-code across cloud native environments.
Originally created by Nirmata and contributed to the CNCF in 2020, Kyverno (which means “to govern” in Greek) has achieved the highest maturity level after demonstrating widespread production adoption and significant community growth. The project’s declarative policy-as-code solution makes it easier for platform and security teams to define and enforce guardrails across Kubernetes and cloud native environments.
“Kyverno’s graduation highlights how important policy-as-code has become for organizations running cloud native in production at scale,” said Chris Aniszczyk, CTO of CNCF. “The project makes it easier for platform teams to enforce governance and security practices using familiar Kubernetes constructs, and the strong community behind Kyverno shows how critical this capability is across the ecosystem.”
Since joining the CNCF, Kyverno has experienced exponential growth and adoption across the Kubernetes ecosystem. The project has grown from 574 to more than 9,000 GitHub stars, and Kyverno continues to attract a growing number of contributors and end users worldwide. Today, Kyverno helps platform and security teams enforce policy, security and operational guardrails across some of the world’s largest Kubernetes environments. Organizations such as Bloomberg, Coinbase, Deutsche Telekom, Groww, LinkedIn, Spotify, Vodafone and Wayfair publicly rely on Kyverno to help secure and manage their Kubernetes platforms.
The project offers multiple ways for organizations to integrate policy management into their workflows, including running as a Kubernetes admission controller, command-line interface (CLI), container image or software development kit (SDK). While Kyverno began as a Kubernetes-native admission controller, it has evolved into a broader policy engine used across the cloud native stack. Declarative policies can now be applied to a wide range of payloads and enforcement points. It integrates deeply with the broader CNCF ecosystem and is commonly used alongside projects such as Argo CD, Backstage, Flux and Kubernetes to help platform teams implement policy-driven governance as part of modern GitOps and platform engineering practices.
To achieve graduation, Kyverno successfully completed a third party security audit and a comprehensive security assessment led by CNCF TAG Security & Compliance. The project also passed a formal governance review, demonstrating mature open source practices. Further, the community introduced contributor guidelines addressing the responsible use of AI-assisted development tools.
The CNCF Technical Oversight Committee (TOC) provides technical leadership to the cloud native community, defining its vision and stewarding projects through maturity levels up to graduation. Kyverno’s graduation was supported by TOC sponsor Karena Angell, who conducted a thorough technical due diligence.
“Graduation is reserved for projects that demonstrate strong governance, sustained community growth and widespread production use,” said Karena Angell, chair of the Technical Oversight Committee, CNCF. “Kyverno met that bar through its technical maturity, security posture and the growing number of organizations relying on it to manage policy across Kubernetes environments.”
With its latest release, Kyverno has fully adopted Common Expression Language (CEL), aligning with the future direction of Kubernetes admission controls for improved performance and enhanced expressiveness. Upcoming releases will focus on extending policy enforcement to additional control points across the cloud native stack, including support for artificial intelligence and Model Context Protocol (MCP) gateways. These innovations will help organizations apply policy-as-code consistently across infrastructure, applications and emerging AI-driven workloads.
“As AI adoption accelerates, policy-as-code provides the essential guardrails for autonomous governance at scale without stifling innovation,” said Jim Bugwadia, Kyverno co-creator and CEO of Nirmata. “We built Kyverno to champion developer agility and self-service, and we are honored by its massive growth and success within the CNCF ecosystem.”
Learn more about Kyverno and join the community: https://kyverno.io
Supporting Quotes
“Kyverno has become a core part of how I help platform teams take control of their Kubernetes environments. What used to require manual intervention and custom scripts is now policy-as-code that teams can own without learning a separate language. For organisations running Kubernetes at scale, Kyverno’s graduation reflects what I’ve seen firsthand – it’s production-ready, battle-tested and it makes platform teams faster.”
– Steve Wade, Founder at Platform Fix and Ex-Technical Advisory Board Member at Cisco
“At Deutsche Telekom, Kyverno has played an important role in helping our platform teams implement Kubernetes-native policy management in a scalable and developer-friendly way. Its declarative approach to policy enforcement allows us to embed security, compliance and operational best practices directly into our Kubernetes environments without adding unnecessary complexity for application teams. The project’s strong community, rapid innovation and focus on usability have made Kyverno a valuable tool for organizations operating Kubernetes at scale. We’re excited to see the project reach this stage and look forward to its continued growth in the cloud native ecosystem.”
– Mamta Bharti, VP of Engineering at Deutsche Telekom
“Kyverno has become a critical component of LinkedIn’s Kubernetes admission control pipeline, enforcing consistent security and configuration policies across 230+ clusters with 500K+ nodes. Its YAML-native approach means our platform teams can author and maintain policies without learning a new language. Kyverno has proven its reliability at enterprise scale, handling over 20K admission requests per minute under stress without degradation.”
– Shan Velleru, Senior Software Engineer at LinkedIn
About Cloud Native Computing Foundation
Cloud native computing empowers organizations to build and run scalable applications with an open source software stack in public, private, and hybrid clouds. The Cloud Native Computing Foundation (CNCF) hosts critical components of the global technology infrastructure, including Kubernetes, Prometheus, and Envoy. CNCF brings together the industry’s top developers, end users, and vendors and runs the largest open source developer conferences in the world. Supported by nearly 800 members, including the world’s largest cloud computing and software companies, as well as over 200 innovative startups, CNCF is part of the nonprofit Linux Foundation. For more information, please visit www.cncf.io.
###
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our trademark usage page. Linux is a registered trademark of Linus Torvalds.
Media Contact
Haley White
The Linux Foundation
CNCF and SlashData Report Finds Platform Engineering Tools Maturing as Organizations Prepare for AI-Driven Infrastructure
New CNCF Technology Radar survey shows which cloud native tools developers view as mature and ready for broad adoption
Key Highlights:
- CNCF and SlashData release findings from the Q1 2026 CNCF Technology Radar survey based on responses from more than 400 professional developers.
- CNCF and SlashData’s new report highlights which cloud native platform engineering tools developers who were surveyed view as mature, useful and ready for broad adoption.
- Helm, Backstage and kro are the three technologies placed in the ‘Adopt’ position of the application delivery technology radar, based on survey responses.
- Hybrid platform approaches are emerging as the dominant model for AI workflows, reflecting how organizations are adapting existing developer platforms to support AI workloads.
AMSTERDAM, KUBECON + CLOUDNATIVECON EUROPE– March 24, 2026 – The Cloud Native Computing Foundation® (CNCF®), which builds sustainable ecosystems for cloud native software, released new findings from the Q1 2026 CNCF Technology Radar report with SlashData, uncovering how developers are evaluating platform engineering technologies for workflow automation, application delivery, security and compliance management.
The survey findings provide an overview of how cloud native teams select internal platform tooling as organizations scale application delivery and prepare infrastructure for artificial intelligence (AI) workloads and increasingly automated development environments.
“Cloud native platforms have reached a point where developers are not just experimenting but standardizing on CNCF projects that make software delivery reliable at scale,” said Chris Aniszczyk, CTO, CNCF. “What’s especially notable about this research is how organizations are extending those same platforms to support AI workloads, showing how cloud native is the base layer of powering the next era of applications.”
Platform Engineering Shapes AI Workflow Strategies
The report explores how organizations structure internal developer platforms (IDPs) and how these decisions influence their approach to AI workflows.
- 28% of organizations report having a dedicated platform engineering team responsible for internal platforms.
- The most common IDP model, reported by 41% of organizations, is multi-team collaboration for managing platform capabilities.
- 35% of organizations report using a hybrid platform to integrate AI workloads, combining existing developer platforms with specialized AI tooling.
These survey findings suggest that many organizations are integrating AI capabilities directly into their cloud native platforms, rather than creating entirely new infrastructure stacks.
Workflow Automation Tools Show Strong Developer Confidence
In the workflow automation category, developers identify several technologies as reliable options for production environments, placing ArgoCD, Armada, Buildpacks, GitHub Actions, Jenkins in the ‘Adopt’ category.
- GitHub Actions received high recommendations across maturity and usefulness metrics, with 91% of developers claiming that they would recommend it to peers.
- Jenkins demonstrated strong maturity scores, reflecting its long standing role in CI/CD
- Developers gave Karmada and other newer tools high maturity ratings. Karmada achieved the highest usefulness rating among workflow automation tools.
The report also highlights that emerging tools are attracting developer interest, even as they continue to mature, suggesting strong developer enthusiasm for multicluster management solutions despite the perception that the technology is still evolving.
Security and Compliance Tooling Becomes Core Platform Infrastructure
According to the survey findings, security and compliance technologies are emerging as core components of modern developer platforms. Developers placed cert-manager, Keycloak, Open Policy Agent (OPA) in the ‘Adopt’ category.
- cert-manager received the highest maturity ratings, with 87% of developers rating it four to five stars for stability and reliability.
- Tools addressing emerging areas such as software supply chain security are gaining attention but remain early in their maturity cycle. For example, in-toto and Sigstore showed lower maturity ratings with little negative sentiment.
These findings suggest that developers are still evaluating how these solutions fit into their development pipelines.
Application Delivery Platforms Continue to Standardize
In the application delivery category, Backstage, Helm, and kro were placed in the ‘adopt’ position, reflecting strong developer confidence in these projects.
- Helm received the highest maturity ratings among application delivery tools, with 94% of developers giving it the greatest number of four- and five-star ratings for reliability and stability.
- Helm’s widespread usage across the ecosystem reinforces its role as a foundational component of Kubernetes application deployment.
- Backstage and kro performed strongly in usefulness ratings.
These findings indicate continued developer demand for tools that simplify Kubernetes complexity and improve developer experience across internal platforms.
“Developers are increasingly evaluating tools based on how well they fit into their internal platform architectures,” said Liam Bollmann-Dodd, principal market research consultant at SlashData. “What we see in this data is those technologies gaining traction are the ones that are reducing operational friction while enabling teams to standardize application delivery and management.”
Methodology
In Q4 2025, more than 400 professional developers using cloud native technologies were surveyed about their experiences with workflow automation, application delivery and security and compliance management tools. Respondents evaluated technologies they were familiar with based on their maturity, usefulness and the likelihood of recommending them.
Additional Resources:
- Download the full Technology Radar report
- Learn more about CNCF projects at https://www.cncf.io/projects/
About Cloud Native Computing Foundation
Cloud native computing empowers organizations to build and run scalable applications with an open source software stack in public, private, and hybrid clouds. The Cloud Native Computing Foundation (CNCF) hosts critical components of the global technology infrastructure, including Kubernetes, Prometheus, and Envoy. CNCF brings together the industry’s top developers, end users, and vendors and runs the largest open source developer conferences in the world. Supported by nearly 800 members, including the world’s largest cloud computing and software companies, as well as over 200 innovative startups, CNCF is part of the nonprofit Linux Foundation. For more information, please visit www.cncf.io.
About SlashData
SlashData is an analyst firm with more than 20 years of experience in the software industry, working with the top Tech brands. SlashData helps platform and engineering leaders make better product, marketing and strategy decisions through best-in-class research, benchmarks, and foresight into how developers, tools, and software are changing.
###
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our trademark usage page. Linux is a registered trademark of Linus Torvalds.
Media Contact
Haley White
The Linux Foundation
Welcome llm-d to the CNCF: Evolving Kubernetes into SOTA AI infrastructure
We are thrilled to announce that llm-d has officially been accepted as a Cloud Native Computing Foundation (CNCF) Sandbox project!
As generative AI transitions from research labs to production environments, platform engineering teams are facing a new frontier of infrastructure challenges. llm-d is joining the CNCF to lead the evolution of Kubernetes and the broader CNCF landscape into State of the Art (SOTA) AI infrastructure, treating distributed inference as a first-class cloud native workload. By joining the CNCF, llm-d secures the trusted stewardship and open governance of the Linux Foundation, giving organizations the confidence to build upon a truly neutral standard.
Launched in May 2025 as a collaborative effort between Red Hat, Google Cloud, IBM Research, CoreWeave, and NVIDIA, llm-d was founded with a clear vision: any model, any accelerator, any cloud. The project was joined by industry leaders AMD, Cisco, Hugging Face, Intel, Lambda and Mistral AI and university supporters at the University of California, Berkeley, and the University of Chicago.
“At Mistral AI, we believe that optimizing inference goes beyond just the engine, and requires solving challenges like KV cache management and disaggregated serving to support next-generation models such as Mixture of Experts (MoE). Open collaboration on these issues is essential to building flexible, future-proof infrastructure. We’re supporting this effort by contributing to the llm-d ecosystem, including the development of a DisaggregatedSet operator for LeaderWorkerSet (LWS), to help advance open standards for AI serving.” – Mathis Felardos, Inference Software Engineer, Mistral AI
What llm-d brings to the CNCF landscape
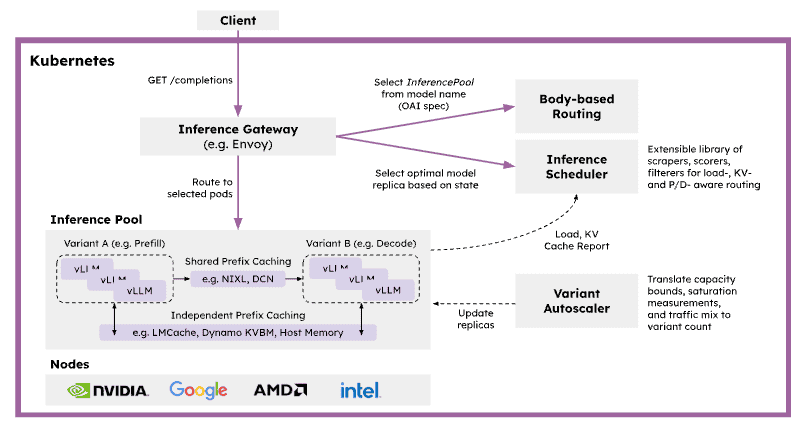
The CNCF is the natural home for solving complex workload orchestration challenges. AI serving is highly stateful and latency-sensitive, with request costs varying dramatically based on prompt length, cache locality, and model phase. Traditional service routing and autoscaling mechanisms are unaware of this inference state, leading to inefficient placement, cache fragmentation, and unpredictable latency under load. llm-d solves this by providing a pre-integrated, Kubernetes-native distributed inference framework that bridges the gap between high-level control planes (like KServe) and low-level inference engines (like vLLM). llm-d plans to work with the CNCF AI Conformance program to ensure critical capabilities like disaggregated serving are interoperable across the ecosystem.
By building on open APIs and extensible gateway primitives, llm-d introduces several critical capabilities to the CNCF ecosystem:
- Inference-Aware Traffic Management: Acting as a primary implementation of the Kubernetes Gateway API Inference Extension (GAIE), llm-d utilizes the Endpoint Picker (EPP) for programmable, prefix-cache-aware routing.
- Native Kubernetes Orchestration: Leveraging primitives like LeaderWorkerSet (LWS), llm-d orchestrates complex multi-node replicas and wide expert parallelism, transforming bespoke AI infrastructure into manageable cloud native microservices.
- Prefill/Decode Disaggregation: llm-d addresses the resource-utilization asymmetry between prompt processing and token generation by disaggregating these phases into independently scalable pods.
Advanced State Management: The project introduces hierarchical KV cache offloading across GPU, TPU, CPU, and storage tiers.
SOTA inference performance on any accelerator
A core tenet of the cloud native philosophy is preventing vendor lock-in. For AI infrastructure, this means serving capabilities must be hardware-agnostic.
We believe that democratizing SOTA inference with an accelerator-neutral mindset is the most important enabler for broad LLM adoption. The primary mission of llm-d is to Achieve SOTA Inference Performance On Any Accelerator. By introducing model- and state-aware routing policies that align request placement with specific hardware characteristics, llm-d maximizes utilization and delivers measurable gains in critical inference metrics like Time to First Token (TTFT), Time Per Output Token (TPOT), token throughput, and KV cache utilization. Whether you are running workloads on accelerators from NVIDIA, AMD, or Google, llm-d ensures that high-performance AI serving remains a core, composable capability of your stack.
Crucially, clear benchmarks that prove the value of these optimizations are core to the project. The AI industry often lacks standard, reproducible ways to measure inference performance, relying instead on marketing claims or commercial analysts. llm-d aims to be the neutral, de facto standard for defining and running inference benchmarks through rigorous, open benchmarking. For example, in a ‘Multi-tenant SaaS’ use case, shared customer contexts enable significant computational savings through prefix caching. As demonstrated in the most recent v0.5 release, llm-d’s inference scheduling maintains near-zero latency and massive throughput compared to a baseline Kubernetes service:
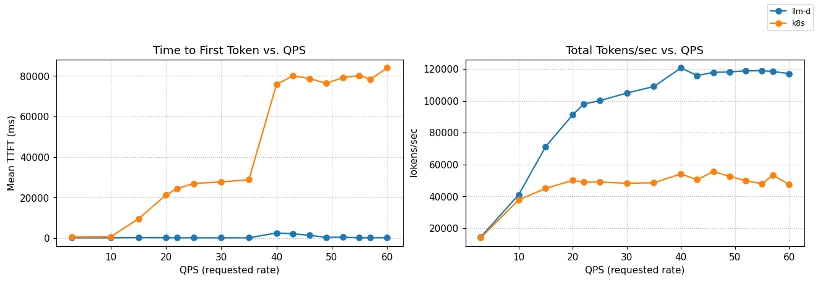
Figure 1: TTFT and throughput vs QPS on Qwen3-32B (8×vLLM pods, 16×NVIDIA H100).
llm-d inference scheduling maintains near-zero TTFT and scales to ~120k tok/s,
while baseline Kubernetes service degrades rapidly under load.
Bridging cloud native and AI native ecosystems
To build the ultimate AI infrastructure, we must bridge the gap between Kubernetes orchestration and frontier AI research. llm-d is actively building deep relationships with AI/ML leaders at large foundation model builders and AI natives, along with traditional enterprises that are rapidly integrating AI throughout their organizations. Furthermore, we are committed to increasing collaboration with the PyTorch Foundation to ensure a seamless, end-to-end open ecosystem that connects model development and training directly to distributed cloud native serving.
Get involved: Follow the “well-lit paths”
At its core, llm-d follows a “well-lit paths” philosophy. Instead of leaving platform teams to piece together fragile black boxes, llm-d provides validated, production-ready deployment patterns—benchmarked recipes tested end-to-end under realistic load.
We invite developers, platform engineers, and AI researchers to join us in shaping the future of open AI infrastructure:
- Explore the Well-Lit Paths: Visit the llm-d guides to start deploying SOTA inference stacks on your infrastructure today.
- Learn More: Check out the official website at llm-d.ai.
- Contribute: Join the community on slack and get involved in our GitHub repositories at https://github.com/llm-d/.
Welcome to the CNCF, llm-d! We look forward to building the future of AI infrastructure together.
What does “AI security” mean and why does it matter to your business?
‘CanisterWorm’ Springs Wiper Attack Targeting Iran
A financially motivated data theft and extortion group is attempting to inject itself into the Iran war, unleashing a worm that spreads through poorly secured cloud services and wipes data on infected systems that use Iran’s time zone or have Farsi set as the default language.
Experts say the wiper campaign against Iran materialized this past weekend and came from a relatively new cybercrime group known as TeamPCP. In December 2025, the group began compromising corporate cloud environments using a self-propagating worm that went after exposed Docker APIs, Kubernetes clusters, Redis servers, and the React2Shell vulnerability. TeamPCP then attempted to move laterally through victim networks, siphoning authentication credentials and extorting victims over Telegram.
A snippet of the malicious CanisterWorm that seeks out and destroys data on systems that match Iran’s timezone or have Farsi as the default language. Image: Aikido.dev.
In a profile of TeamPCP published in January, the security firm Flare said the group weaponizes exposed control planes rather than exploiting endpoints, predominantly targeting cloud infrastructure over end-user devices, with Azure (61%) and AWS (36%) accounting for 97% of compromised servers.
“TeamPCP’s strength does not come from novel exploits or original malware, but from the large-scale automation and integration of well-known attack techniques,” Flare’s Assaf Morag wrote. “The group industrializes existing vulnerabilities, misconfigurations, and recycled tooling into a cloud-native exploitation platform that turns exposed infrastructure into a self-propagating criminal ecosystem.”
On March 19, TeamPCP executed a supply chain attack against the vulnerability scanner Trivy from Aqua Security, injecting credential-stealing malware into official releases on GitHub actions. Aqua Security said it has since removed the harmful files, but the security firm Wiz notes the attackers were able to publish malicious versions that snarfed SSH keys, cloud credentials, Kubernetes tokens and cryptocurrency wallets from users.
Over the weekend, the same technical infrastructure TeamPCP used in the Trivy attack was leveraged to deploy a new malicious payload which executes a wiper attack if the user’s timezone and locale are determined to correspond to Iran, said Charlie Eriksen, a security researcher at Aikido. In a blog post published on Sunday, Eriksen said if the wiper component detects that the victim is in Iran and has access to a Kubernetes cluster, it will destroy data on every node in that cluster.
“If it doesn’t it will just wipe the local machine,” Eriksen told KrebsOnSecurity.

Image: Aikido.dev.
Aikido refers to TeamPCP’s infrastructure as “CanisterWorm” because the group orchestrates their campaigns using an Internet Computer Protocol (ICP) canister — a system of tamperproof, blockchain-based “smart contracts” that combine both code and data. ICP canisters can serve Web content directly to visitors, and their distributed architecture makes them resistant to takedown attempts. These canisters will remain reachable so long as their operators continue to pay virtual currency fees to keep them online.
Eriksen said the people behind TeamPCP are bragging about their exploits in a group on Telegram and claim to have used the worm to steal vast amounts of sensitive data from major companies, including a large multinational pharmaceutical firm.
“When they compromised Aqua a second time, they took a lot of GitHub accounts and started spamming these with junk messages,” Eriksen said. “It was almost like they were just showing off how much access they had. Clearly, they have an entire stash of these credentials, and what we’ve seen so far is probably a small sample of what they have.”
Security experts say the spammed GitHub messages could be a way for TeamPCP to ensure that any code packages tainted with their malware will remain prominent in GitHub searches. In a newsletter published today titled GitHub is Starting to Have a Real Malware Problem, Risky Business reporter Catalin Cimpanu writes that attackers often are seen pushing meaningless commits to their repos or using online services that sell GitHub stars and “likes” to keep malicious packages at the top of the GitHub search page.
This weekend’s outbreak is the second major supply chain attack involving Trivy in as many months. At the end of February, Trivy was hit as part of an automated threat called HackerBot-Claw, which mass exploited misconfigured workflows in GitHub Actions to steal authentication tokens.
Eriksen said it appears TeamPCP used access gained in the first attack on Aqua Security to perpetrate this weekend’s mischief. But he said there is no reliable way to tell whether TeamPCP’s wiper actually succeeded in trashing any data from victim systems, and that the malicious payload was only active for a short time over the weekend.
“They’ve been taking [the malicious code] up and down, rapidly changing it adding new features,” Eriksen said, noting that when the malicious canister wasn’t serving up malware downloads it was pointing visitors to a Rick Roll video on YouTube.
“It’s a little all over the place, and there’s a chance this whole Iran thing is just their way of getting attention,” Eriksen said. “I feel like these people are really playing this Chaotic Evil role here.”
Cimpanu observed that supply chain attacks have increased in frequency of late as threat actors begin to grasp just how efficient they can be, and his post documents an alarming number of these incidents since 2024.
“While security firms appear to be doing a good job spotting this, we’re also gonna need GitHub’s security team to step up,” Cimpanu wrote. “Unfortunately, on a platform designed to copy (fork) a project and create new versions of it (clones), spotting malicious additions to clones of legitimate repos might be quite the engineering problem to fix.”
Update, 2:40 p.m. ET: Wiz is reporting that TeamPCP also pushed credential stealing malware to the KICS vulnerability scanner from Checkmarx, and that the scanner’s GitHub Action was compromised between 12:58 and 16:50 UTC today (March 23rd).
Microsoft Xbox One Hacked
It’s an impressive feat, over a decade after the box was released:
Since reset glitching wasn’t possible, Gaasedelen thought some voltage glitching could do the trick. So, instead of tinkering with the system rest pin(s) the hacker targeted the momentary collapse of the CPU voltage rail. This was quite a feat, as Gaasedelen couldn’t ‘see’ into the Xbox One, so had to develop new hardware introspection tools.
Eventually, the Bliss exploit was formulated, where two precise voltage glitches were made to land in succession. One skipped the loop where the ...
Beyond Batch: Volcano Evolves into the AI-Native Unified Scheduling Platform
The world of AI workloads is changing fast. A few years ago, “AI on Kubernetes” mostly meant running long training jobs. Today, with the rise of Large Language Models (LLMs), the focus has shifted to include complex inference services and Autonomous Agents. The industry consensus, backed by CNCF’s latest Annual Cloud Native Survey, is clear: Kubernetes has evolved to become the essential platform for intelligent systems. This shift from traditional training jobs to real-time inference and agents is transforming cloud native infrastructure.
This shift creates new challenges:
- Complex Inference Demands: Serving LLMs requires high-performance GPU resources and sophisticated management to control costs and latency.
- Distinct Agent Requirements: AI Agents introduce “bursty” traffic patterns, requiring instant startup times and state preservation—capabilities not natively optimized in Kubernetes.
The Volcano community is responding to these needs. With the release of Volcano v1.14, Kthena v0.3.0, and the new AgentCube, Volcano is transforming from a batch computing tool into a Full-Scenario, AI-Native Unified Scheduling Platform.
1. Volcano v1.14: Breaking Limits on Scale and Speed
As clusters expand and workloads diversify, scheduler bottlenecks can degrade performance. Volcano v1.14 introduces a major architectural evolution to address this.
Scalable Multi-Scheduler Architecture
Traditional setups often rely on static resource division, leading to wasted capacity. Volcano v1.14 introduces a Sharding Controller that dynamically calculates resource pools for different schedulers (Batch, Agent, etc.) in real-time.
- Key Benefit: Enables running latency-sensitive Agent tasks alongside massive training jobs on the same cluster without resource contention, ensuring high cluster utilization and cost efficiency.
High-Throughput Agent Scheduling
Standard Kubernetes scheduling often struggles with the high churn rate of AI Agents. The new Agent Scheduler (Alpha) in v1.14 provides a high-performance fast path designed specifically for short-lived, high-concurrency tasks.
Enhanced Resource Efficiency
To optimize infrastructure costs, v1.14 adds support for generic Linux OSs (Ubuntu, CentOS) and democratizes enterprise features like CPU Throttling and Memory QoS. Additionally, native support for Ascend vNPU maximizes the utilization of diverse AI hardware.
2. Kthena v0.3.0: Efficient and Scalable LLM Serving
The CNCF survey has identified AI inference as the next major cloud native workload, representing the bulk of long-term cost, value, and complexity. Kthena v0.3.0 directly addresses this challenge, introducing a specialized Data Plane and Control Plane architecture to solve the speed and cost balance for serving large models.
Optimized Prefill-Decode Disaggregation
Separating “Prefill” and “Decode” phases improves efficiency but introduces heavy cross-node traffic.
- Key Benefit: Kthena leverages Network Topology Awareness to co-locate interdependent tasks (e.g., on the same switch). Combined with a Smart Router that recognizes KV-Cache and LoRA adapters, it ensures requests are routed with minimal latency and maximum throughput.
Simplified Deployment with ModelBooster
Deploying large models typically involves managing fragmented Kubernetes resources.
- Key Benefit: The new ModelBooster feature offers a declarative, one-stop deployment experience. Users define the model intent once, and Kthena automates the provisioning and lifecycle management of all underlying resources, significantly reducing operational complexity.
Cost-Efficient Heterogeneous Autoscaling
Running LLMs exclusively on top-tier GPUs can be cost-prohibitive.
- Key Benefit: Kthena’s autoscaler supports Heterogeneous Scaling, allowing the mixing of different hardware types (e.g., high-end vs. cost-effective GPUs) within strict budget constraints, optimizing the balance between performance and expenditure.
3. AgentCube: Serverless Infrastructure for AI Agents
While Kubernetes provides a solid infrastructure foundation, it lacks specific primitives for AI Agents. AgentCube bridges this gap with specialized capabilities.
Instant Startup via Warm Pools
Agents require immediate responsiveness that standard container startup times cannot match.
- Key Benefit: AgentCube utilizes a Warm Pool of lightweight MicroVM sandboxes. This mechanism reduces startup latency from seconds to milliseconds, delivering the snappy experience users expect.
Native Session Management
AI Agents require state persistence across multi-turn interactions, unlike typical stateless microservices.
- Key Benefit: Built-in Session Management automatically routes conversations to the correct context, seamlessly enabling stateful interactions within a stateless Kubernetes environment.
Serverless Abstraction
Developers need to focus on agent logic rather than server management.
- Key Benefit: AgentCube provides a streamlined API for requesting secure environments (like Code Interpreters). It handles the entire lifecycle—secure creation, execution, and automated recycling—offering a true serverless experience.
Conclusion
Volcano has evolved beyond batch jobs. With v1.14, Kthena, and AgentCube, we now provide a comprehensive platform for the entire AI lifecycle—from training foundation models to serving them at scale to powering the next generation of intelligent agents.
By embracing cloud native principles to deliver scalable, reliable infrastructure for the AI lifecycle, Volcano is contributing to the community’s goal of ensuring AI workloads behave predictably at scale. As organizations seek consistent and portable AI infrastructure (a concept championed by initiatives like the Kubernetes AI Conformance Program), Volcano is positioning itself as a core component of that solution.
We invite you to explore these new features and join us in building the future of AI infrastructure.
- Volcano GitHub: github.com/volcano-sh/volcano
- Kthena GitHub: github.com/volcano-sh/kthena
- AgentCube GitHub: github.com/volcano-sh/agentcube
If you are attending KubeCon + CloudNativeCon Europe, we encourage you to stop by our booth, P-14A, in the Project Pavilion to say hi and learn more about the latest updates.
Metal3 at KubeCon + CloudNativeCon Europe 2026: Meet the CNCF’s Freshly Incubated Bare Metal Project
Metal3 (pronounced “metal cubed”) entered 2026 as one of the newest incubating projects in the CNCF. As the foundational layer for infrastructure management in self-hosted Kubernetes clouds, Metal3 and its ‘stack’ offer essential solutions for cloud service providers, AI-focused distributed systems, edge cloud deployments, and telecom infrastructure. Given the increasing investment in compute infrastructure worldwide, Metal3 addresses a growing number of issues faced by the modern IT industry.
From the start, Metal3 set the ambitious goal of becoming the primary tool for Kubernetes bare metal cluster management across the broader cloud native ecosystem. Real-world feedback is necessary to achieve this, and the community remains committed to increasing the project’s visibility and adoption. Metal3 is at the forefront of automated bare metal lifecycle management and the community is aiming to assist others in achieving the same level of success.
If you’re attending, KubeCon + CloudNativeCon Europe is the perfect opportunity to get better acquainted with Metal3, ask questions, and connect with maintainers and community members. This year’s conference will be one of the most active events yet for Metal3 ever, with a record number of talks and touchpoints for anyone interested in learning about the project.
A packed Metal3 presence at KubeCon + CloudNativeCon Europe
Metal3 has organized a packed presence at the conference, offering a variety of opportunities for attendees to engage with the project. For a quick overview, a concise project status update will be delivered during the lightning talk. For those interested in deeper engagement, there are two in-depth sessions focusing on the project’s governance and path to CNCF Incubation and a real-world adoption use case from the Sylva Project. Additionally, you can meet maintainers and community members for questions and hallway-track conversations at the Metal3 kiosk on the Solutions Showcase floor.
Lightning talk
The first event of the week, a lightning talk, will take place on Monday, 23 March. In classic Metal3 fashion, the community will share a quick status report of the Metal3 project, focusing on future plans toward graduation and beyond, along with highlights of major developments on the roadmap.
If you’re new to Metal3, this session is a great entry point; it’s short, focused, and gives you the “what’s happening” overview you need before you take a deeper dive.
Two in-depth sessions: governance and adoption
In addition to the lightning talk, community members will be presenting two more in-depth sessions around Metal3 governance and adoption.
1) Metal3.io’s Path to CNCF Incubation: Governance, Processes, and Community
Presented by Metal3 maintainers, this session focuses on Metal3’s journey from CNCF Sandbox to Incubation through the lens of governance, processes, and community building.
Be sure to attend if you’re interested in:
- How Metal3 is run as an open-source project
- What changed (or matured) during incubation readiness
- How decisions are made and contributions flow
2) Beyond the Cloud: Managing Bare Metal the Kubernetes Way Using Metal3.io: Sylva Project as a Use Case
This talk approaches Metal3 from the viewpoint of an adopter. The hosts will explain the operational reality and practical use cases of a telco project and Metal3’s role.
Don’t miss this session if you care about:
- What adopting Metal3 looks like in practice
- The value proposition of Kubernetes-native bare metal lifecycle management
- Lessons learned and patterns from real usage in a telco project
Visit the Metal3 kiosk
You can also meet maintainers and community members at the Metal3 kiosk P-21B on the Solutions Showcase floor, from Tuesday, 24 March, to the morning of Thursday, 26 March. This is a great opportunity to connect directly with the people building and operating the project. Whether you have technical queries about implementation, operational questions about running Metal3 in production, governance-related inquiries about its CNCF journey, or if you are simply curious about the project’s future, the kiosk is one of the easiest ways to get answers and context quickly.
Join the conversation
Whether you’re attending KubeCon + CloudNativeCon Europe to learn, evaluate, contribute to, or compare approaches for managing the lifecycle of bare metal Kubernetes, this event is shaping up to be a key moment for Metal3.
Stop by the kiosk, catch the lightning talk, and join one (or both!) of the longer sessions
The community is eager to meet users and contributors and to discuss the future of bare metal Kubernetes. We welcome new contributors and adopters to our continuously growing community, inviting everyone working with bare metal Kubernetes to share their use cases and feedback. Whether you are already running Metal3 in production or just starting to explore, the community welcomes everyone’s input as an adopter, operator, or contributor. Learn more about how you can get active by visiting: https://metal3.io/contribute.html
See you at the conference!
Fastly at RSAC 2026: New Advances in AppSec, Bot Management, and Deception
Friday Squid Blogging: Jumbo Flying Squid in the South Pacific
The population needs better conservation.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Announcing Ingress2Gateway 1.0: Your Path to Gateway API
With the Ingress-NGINX retirement scheduled for March 2026, the Kubernetes networking landscape is at a turning point. For most organizations, the question isn't whether to migrate to Gateway API, but how to do so safely.
Migrating from Ingress to Gateway API is a fundamental shift in API design. Gateway API provides a modular, extensible API with strong support for Kubernetes-native RBAC. Conversely, the Ingress API is simple, and implementations such as Ingress-NGINX extend the API through esoteric annotations, ConfigMaps, and CRDs. Migrating away from Ingress controllers such as Ingress-NGINX presents the daunting task of capturing all the nuances of the Ingress controller, and mapping that behavior to Gateway API.
Ingress2Gateway is an assistant that helps teams confidently move from Ingress to Gateway API. It translates Ingress resources/manifests along with implementation-specific annotations to Gateway API while warning you about untranslatable configuration and offering suggestions.
Today, SIG Network is proud to announce the 1.0 release of Ingress2Gateway. This milestone represents a stable, tested migration assistant for teams ready to modernize their networking stack.
Ingress2Gateway 1.0
Ingress-NGINX annotation support
The main improvement for the 1.0 release is more comprehensive Ingress-NGINX support. Before the 1.0 release, Ingress2Gateway only supported three Ingress-NGINX annotations. For the 1.0 release, Ingress2Gateway supports over 30 common annotations (CORS, backend TLS, regex matching, path rewrite, etc.).
Comprehensive integration testing
Each supported Ingress-NGINX annotation, and representative combinations of common annotations, is backed by controller-level integration tests that verify the behavioral equivalence of the Ingress-NGINX configuration and the generated Gateway API. These tests exercise real controllers in live clusters and compare runtime behavior (routing, redirects, rewrites, etc.), not just YAML structure.
The tests:
- spin up an Ingress-NGINX controller
- spin up multiple Gateway API controllers
- apply Ingress resources that have implementation-specific configuration
- translate Ingress resources to Gateway API with
ingress2gatewayand apply generated manifests - verify that the Gateway API controllers and the Ingress controller exhibit equivalent behavior.
A comprehensive test suite not only catches bugs in development, but also ensures the correctness of the translation, especially given surprising edge cases and unexpected defaults, so that you don't find out about them in production.
Notification & error handling
Migration is not a "one-click" affair. Surfacing subtleties and untranslatable behavior is as important as translating supported configuration. The 1.0 release cleans up the formatting and content of notifications, so it is clear what is missing and how you can fix it.
Using Ingress2Gateway
Ingress2Gateway is a migration assistant, not a one-shot replacement. Its goal is to
- migrate supported Ingress configuration and behavior
- identify unsupported configuration and suggest alternatives
- reevaluate and potentially discard undesirable configuration
The rest of the section shows you how to safely migrate the following Ingress-NGINX configuration
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: "1G"
nginx.ingress.kubernetes.io/use-regex: "true"
nginx.ingress.kubernetes.io/proxy-send-timeout: "1"
nginx.ingress.kubernetes.io/proxy-read-timeout: "1"
nginx.ingress.kubernetes.io/enable-cors: "true"
nginx.ingress.kubernetes.io/configuration-snippet: |
more_set_headers "Request-Id: $req_id";
name: my-ingress
namespace: my-ns
spec:
ingressClassName: nginx
rules:
- host: my-host.example.com
http:
paths:
- backend:
service:
name: website-service
port:
number: 80
path: /users/(\d+)
pathType: ImplementationSpecific
tls:
- hosts:
- my-host.example.com
secretName: my-secret
1. Install Ingress2Gateway
If you have a Go environment set up, you can install Ingress2Gateway with
go install github.com/kubernetes-sigs/[email protected]
Otherwise,
brew install ingress2gateway
You can also download the binary from GitHub or build from source.
2. Run Ingress2Gateway
You can pass Ingress2Gateway Ingress manifests, or have the tool read directly from your cluster.
# Pass it files
ingress2gateway print --input-file my-manifest.yaml,my-other-manifest.yaml --providers=ingress-nginx > gwapi.yaml
# Use a namespace in your cluster
ingress2gateway print --namespace my-api --providers=ingress-nginx > gwapi.yaml
# Or your whole cluster
ingress2gateway print --providers=ingress-nginx --all-namespaces > gwapi.yaml
Note:
You can also pass--emitter <agentgateway|envoy-gateway|kgateway> to output implementation-specific extensions.
3. Review the output
This is the most critical step.
The commands from the previous section output a Gateway API manifest to gwapi.yaml, and they also emit warnings that explain what did not translate exactly and what to review manually.
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: nginx
namespace: my-ns
spec:
gatewayClassName: nginx
listeners:
- hostname: my-host.example.com
name: my-host-example-com-http
port: 80
protocol: HTTP
- hostname: my-host.example.com
name: my-host-example-com-https
port: 443
protocol: HTTPS
tls:
certificateRefs:
- group: ""
kind: Secret
name: my-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: my-ingress-my-host-example-com
namespace: my-ns
spec:
hostnames:
- my-host.example.com
parentRefs:
- name: nginx
port: 443
rules:
- backendRefs:
- name: website-service
port: 80
filters:
- cors:
allowCredentials: true
allowHeaders:
- DNT
- Keep-Alive
- User-Agent
- X-Requested-With
- If-Modified-Since
- Cache-Control
- Content-Type
- Range
- Authorization
allowMethods:
- GET
- PUT
- POST
- DELETE
- PATCH
- OPTIONS
allowOrigins:
- '*'
maxAge: 1728000
type: CORS
matches:
- path:
type: RegularExpression
value: (?i)/users/(\d+).*
name: rule-0
timeouts:
request: 10s
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: my-ingress-my-host-example-com-ssl-redirect
namespace: my-ns
spec:
hostnames:
- my-host.example.com
parentRefs:
- name: nginx
port: 80
rules:
- filters:
- requestRedirect:
scheme: https
statusCode: 308
type: RequestRedirect
Ingress2Gateway successfully translated some annotations into their Gateway API equivalents.
For example, the nginx.ingress.kubernetes.io/enable-cors annotation was translated into a CORS filter.
But upon closer inspection, the nginx.ingress.kubernetes.io/proxy-{read,send}-timeout and nginx.ingress.kubernetes.io/proxy-body-size annotations do not map perfectly.
The logs show the reason for these omissions as well as reasoning behind the translation.
┌─ WARN ────────────────────────────────────────
│ Unsupported annotation nginx.ingress.kubernetes.io/configuration-snippet
│ source: INGRESS-NGINX
│ object: Ingress: my-ns/my-ingress
└─
┌─ INFO ────────────────────────────────────────
│ Using case-insensitive regex path matches. You may want to change this.
│ source: INGRESS-NGINX
│ object: HTTPRoute: my-ns/my-ingress-my-host-example-com
└─
┌─ WARN ────────────────────────────────────────
│ ingress-nginx only supports TCP-level timeouts; i2gw has made a best-effort translation to Gateway API timeouts.request. Please verify that this meets your needs. See documentation: https://gateway-api.sigs.k8s.io/guides/http-timeouts/
│ source: INGRESS-NGINX
│ object: HTTPRoute: my-ns/my-ingress-my-host-example-com
└─
┌─ WARN ────────────────────────────────────────
│ Failed to apply my-ns.my-ingress.metadata.annotations."nginx.ingress.kubernetes.io/proxy-body-size" from my-ns/my-ingress: Most Gateway API implementations have reasonable body size and buffering defaults
│ source: STANDARD_EMITTER
│ object: HTTPRoute: my-ns/my-ingress-my-host-example-com
└─
┌─ WARN ────────────────────────────────────────
│ Gateway API does not support configuring URL normalization (RFC 3986, Section 6). Please check if this matters for your use case and consult implementation-specific details.
│ source: STANDARD_EMITTER
└─
There is a warning that Ingress2Gateway does not support the nginx.ingress.kubernetes.io/configuration-snippet annotation.
You will have to check your Gateway API implementation documentation to see if there is a way to achieve equivalent behavior.
The tool also notified us that Ingress-NGINX regex matches are case-insensitive prefix matches, which is why there is a match pattern of (?i)/users/(\d+).*.
Most organizations will want to change this behavior to be an exact case-sensitive match by removing the leading (?i) and the trailing .* from the path pattern.
Ingress2Gateway made a best-effort translation from the nginx.ingress.kubernetes.io/proxy-{send,read}-timeout annotations to a 10 second request timeout in our HTTP route.
If requests for this service should be much shorter, say 3 seconds, you can make the corresponding changes to your Gateway API manifests.
Also, nginx.ingress.kubernetes.io/proxy-body-size does not have a Gateway API equivalent, and was thus not translated.
However, most Gateway API implementations have reasonable defaults for maximum body size and buffering, so this might not be a problem in practice.
Further, some emitters might offer support for this annotation through implementation-specific extensions.
For example, adding the --emitter agentgateway, --emitter envoy-gateway, or --emitter kgateway flag to the previous ingress2gateway print command would have resulted in additional implementation-specific configuration in the generated Gateway API manifests that attempted to capture the body size configuration.
We also see a warning about URL normalization. Gateway API implementations such as Agentgateway, Envoy Gateway, Kgateway, and Istio have some level of URL normalization, but the behavior varies across implementations and is not configurable through standard Gateway API. You should check and test the URL normalization behavior of your Gateway API implementation to ensure it is compatible with your use case.
To match Ingress-NGINX default behavior, Ingress2Gateway also added a listener on port 80 and a HTTP Request redirect filter to redirect HTTP traffic to HTTPS. You may not want to serve HTTP traffic at all and remove the listener on port 80 and the corresponding HTTPRoute.
Caution:
Always thoroughly review the generated output and logs.After manually applying these changes, the Gateway API manifests might look as follows.
---
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: nginx
namespace: my-ns
spec:
gatewayClassName: nginx
listeners:
- hostname: my-host.example.com
name: my-host-example-com-https
port: 443
protocol: HTTPS
tls:
certificateRefs:
- group: ""
kind: Secret
name: my-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
annotations:
gateway.networking.k8s.io/generator: ingress2gateway-dev
name: my-ingress-my-host-example-com
namespace: my-ns
spec:
hostnames:
- my-host.example.com
parentRefs:
- name: nginx
port: 443
rules:
- backendRefs:
- name: website-service
port: 80
filters:
- cors:
allowCredentials: true
allowHeaders:
- DNT
...
allowMethods:
- GET
...
allowOrigins:
- '*'
maxAge: 1728000
type: CORS
matches:
- path:
type: RegularExpression
value: /users/(\d+)
name: rule-0
timeouts:
request: 3s
4. Verify
Now that you have Gateway API manifests, you should thoroughly test them in a development cluster. In this case, you should at least double-check that your Gateway API implementation's maximum body size defaults are appropriate for you and verify that a three-second timeout is enough.
After validating behavior in a development cluster, deploy your Gateway API configuration alongside your existing Ingress. We strongly suggest that you then gradually shift traffic using weighted DNS, your cloud load balancer, or traffic-splitting features of your platform. This way, you can quickly recover from any misconfiguration that made it through your tests.
Finally, when you have shifted all your traffic to your Gateway API controller, delete your Ingress resources and uninstall your Ingress controller.
Conclusion
The Ingress2Gateway 1.0 release is just the beginning, and we hope that you use Ingress2Gateway to safely migrate to Gateway API. As we approach the March 2026 Ingress-NGINX retirement, we invite the community to help us increase our configuration coverage, expand testing, and improve UX.
Resources about Gateway API
The scope of Gateway API can be daunting. Here are some resources to help you work with Gateway API:
- Listener sets allow application developers to manage gateway listeners.
gwctlgives you a comprehensive view of your Gateway resources, such as attachments and linter errors.- Gateway API Slack:
#sig-network-gateway-apion Kubernetes Slack - Ingress2Gateway Slack:
#sig-network-ingress2gatewayon Kubernetes Slack - GitHub: kubernetes-sigs/ingress2gateway
Running Agents on Kubernetes with Agent Sandbox
The landscape of artificial intelligence is undergoing a massive architectural shift. In the early days of generative AI, interacting with a model was often treated as a transient, stateless function call: a request that spun up, executed for perhaps 50 milliseconds, and terminated.
Today, the world is witnessing AI v2 eating AI v1. The ecosystem is moving from short-lived, isolated tasks to deploying multiple, coordinated AI agents that run constantly. These autonomous agents need to maintain context, use external tools, write and execute code, and communicate with one another over extended periods.
As platform engineering teams look for the right infrastructure to host these new AI workloads, one platform stands out as the natural choice: Kubernetes. However, mapping these unique agentic workloads to traditional Kubernetes primitives requires a new abstraction.
This is where the new Agent Sandbox project (currently in development under SIG Apps) comes into play.
The Kubernetes advantage (and the abstraction gap)
Kubernetes is the de facto standard for orchestrating cloud-native applications precisely because it solves the challenges of extensibility, robust networking, and ecosystem maturity. However, as AI evolves from short-lived inference requests to long-running, autonomous agents, we are seeing the emergence of a new operational pattern.
AI agents, by contrast, are typically isolated, stateful, singleton workloads. They act as a digital workspace or execution environment for an LLM. An agent needs a persistent identity and a secure scratchpad for writing and executing (often untrusted) code. Crucially, because these long-lived agents are expected to be mostly idle except for brief bursts of activity, they require a lifecycle that supports mechanisms like suspension and rapid resumption.
While you could theoretically approximate this by stringing together a StatefulSet of size 1, a headless Service, and a PersistentVolumeClaim for every single agent, managing this at scale becomes an operational nightmare.
Because of these unique properties, traditional Kubernetes primitives don't perfectly align.
Introducing Kubernetes Agent Sandbox
To bridge this gap, SIG Apps is developing agent-sandbox. The project introduces a declarative, standardized API specifically tailored for singleton, stateful workloads like AI agent runtimes.
At its core, the project introduces the Sandbox CRD. It acts as a lightweight, single-container environment built entirely on Kubernetes primitives, offering:
- Strong isolation for untrusted code: When an AI agent generates and executes code autonomously, security is paramount. The Sandbox custom resource natively supports different runtimes, like gVisor or Kata Containers. This provides the necessary kernel and network isolation required for multi-tenant, untrusted execution.
- Lifecycle management: Unlike traditional web servers optimized for steady, stateless traffic, an AI agent operates as a stateful workspace that may be idle for hours between tasks. Agent Sandbox supports scaling these idle environments to zero to save resources, while ensuring they can resume exactly where they left off.
- Stable identity: Coordinated multi-agent systems require stable networking. Every Sandbox is given a stable hostname and network identity, allowing distinct agents to discover and communicate with each other seamlessly.
Scaling agents with extensions
Because the AI space is moving incredibly quickly, we built an Extensions API layer that enables even faster iteration and development.
Starting a new pod adds about a second of overhead. That's perfectly fine when deploying a new version of a microservice, but when an agent is invoked after being idle, a one-second cold start breaks the continuity of the interaction. It forces the user or the orchestrating service to wait for the environment to provision before the model can even begin to think or act. SandboxWarmPool solves this by maintaining a pool of pre-provisioned Sandbox pods, effectively eliminating cold starts. Users or orchestration services can simply issue a SandboxClaim against a SandboxTemplate, and the controller immediately hands over a pre-warmed, fully isolated environment to the agent.
Quick start
Ready to try it yourself? You can install the Agent Sandbox core components and extensions directly into your learning or sandbox cluster, using your chosen release.
We recommend you use the latest release as the project is moving fast.
# Replace "vX.Y.Z" with a specific version tag (e.g., "v0.1.0") from
# https://github.com/kubernetes-sigs/agent-sandbox/releases
export VERSION="vX.Y.Z"
# Install the core components:
kubectl apply -f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/${VERSION}/manifest.yaml
# Install the extensions components (optional):
kubectl apply -f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/${VERSION}/extensions.yaml
# Install the Python SDK (optional):
# Create a virtual Python environment
python3 -m venv .venv
source .venv/bin/activate
# Install from PyPI
pip install k8s-agent-sandbox
Once installed, you can try out the Python SDK for AI agents or deploy one of the ready-to-use examples to see how easy it is to spin up an isolated agent environment.
The future of agents is cloud native
Whether it’s a 50-millisecond stateless task, or a multi-week, mostly-idle collaborative process, extending Kubernetes with primitives designed specifically for isolated stateful singletons allows us to leverage all the robust benefits of the cloud-native ecosystem.
The Agent Sandbox project is open source and community-driven. If you are building AI platforms, developing agentic frameworks, or are interested in Kubernetes extensibility, we invite you to get involved:
- Check out the project on GitHub: kubernetes-sigs/agent-sandbox
- Join the discussion in the #sig-apps and #agent-sandbox channels on the Kubernetes Slack.
Proton Mail Shared User Information with the Police
404 Media has a story about Proton Mail giving subscriber data to the Swiss government, who passed the information to the FBI.
It’s metadata—payment information related to a particular account—but still important knowledge. This sort of thing happens, even to privacy-centric companies like Proton Mail.
Crossplane and AI: The case for API-first infrastructure
AI-assisted development has changed the way engineers create and commit code. But writing code is no longer the bottleneck. The bottleneck is everything that happens after git push.
From infrastructure provisioning, policy enforcement, day-two operations, drift, compliance, to cross-team coordination. That still requires multiple steps, and no new tool will fix it. This is an architecture problem. AI needs APIs, not UIs, and most platforms still aren’t built that way.
Current platforms
Talk to almost any organization, and you’ll hear that the desired state lives in Git, while the actual state lives in cloud providers. Policies are buried in pipeline configs. Organizational knowledge exists in wikis no one reads and in engineers who eventually leave.
This has worked up to now because humans worked with humans to navigate the context switching and informal coordination required to get the job done. People fill in the gaps, ask the questions, and translate intent across systems.
But in a world where AI agents are embedded into our organizations, this workflow breaks down. The agent hits a wall, not because it lacks capability, but because the platform wasn’t built for programmatic access. It was built for humans who can compensate for inconsistency.
Agents require a unified, structured, machine-readable interface. They need explicit governance rules, readable historical patterns, and discoverable dependencies. Without that structure, autonomy stalls.

Platforms built on declarative control
Kubernetes introduced a simple but powerful control pattern that changes this entirely. Every resource follows a consistent schema:
yaml
apiVersion: example.crossplane.io/v1
kind: Database
metadata:
name: user-db
spec:
engine: postgres
storage: 100Gi
Desired state lives in spec, actual state is reflected in status, and controllers observe the difference and reconcile continuously. That reconciliation is consistent and automatic; no human is required to coordinate convergence.
Crossplane extends this model beyond containers to all infrastructure and applications: cloud databases, object storage, networking, SaaS systems, clusters, and custom platform APIs. The result isn’t just infrastructure-as-code. It’s your entire platform, infrastructure, and applications as a single API. That difference matters.
The three core elements that make this work in practice:
- Desired state: the declarative specification of what we think the world should be. (Example: The frontend service should have 3 replicas with 2 GB of memory each.)
- Actual state: the operational reality of what exists in the infrastructure. (Example: The frontend service has 2 healthy replicas, 1 pending.)
- Policy: the rules and governance that constrain operations. (Example: Production changes require approval between 9 AM and 5 PM PST.)
Controllers continuously reconcile desired state with actual state, and policy is enforced at execution rather than left to manual review. Context becomes part of the system, not something external to it.
Why this model works for agents
An AI agent interacting with a Crossplane-managed platform doesn’t need to orchestrate workflows across multiple systems. It interacts with a single API surface.
It can discover resource types via the Kubernetes API, inspect status fields for real-time operational state, watch resources for change events, and submit declarative intent. Since reconciliation handles mechanical execution, agents don’t need to coordinate step-by-step logic; they just declare intent and let controllers handle convergence.
This separation of concerns is critical. Controllers handle mechanics, while agents focus on higher-level reasoning. Without a control plane, agents become fragile orchestrators. With one, they become declarative participants.
When the entire platform is accessible through a single, consistent API, the agent has everything it needs. No Slack messages and no tribal knowledge required.
Policy at the point of execution
In fragmented platforms, governance follows lots of procedures: reviews, tickets, Slack threads. In a Kubernetes-native control plane, governance is architectural.
RBAC controls who can act. Admission controllers validate changes before they’re persisted. Policy engines such as OPA and Kyverno enforce constraints at runtime. Crossplane compositions encode organizational patterns directly into APIs. Every change flows through the same enforcement path, no hidden approval steps, no undocumented exception paths.
This removes ambiguity for agents entirely. The system defines what is allowed. Agents operate within clearly defined boundaries, and the platform enforces them automatically.
Crossplane 2.0: Full-stack control
With Crossplane 2.0, compositions can include any Kubernetes resource, not just managed infrastructure. That means a single composite API can provision infrastructure, deploy applications, configure networking, set up observability, and define operational workflows, all in one place.
apiVersion: platform.acme.io/v1
kind: Microservice
metadata:
namespace: team-api
name: user-service
spec:
image: acme/user-service:v1.2.3
database:
engine: postgres
size: medium
ingress:
subdomain: users
Behind that abstraction may live RDS instances, security groups, deployments, services, ingress rules, and monitoring resources. To a human developer or an AI agent, it’s a single API. That consistency is what enables automation to scale safely.
Day-two operations follow the same pattern. Crossplane’s Operation types bring declarative control to scheduled upgrades, backups, maintenance, and event-driven automation:
apiVersion: ops.crossplane.io/v1alpha1
kind: CronOperation
metadata:
name: weekly-db-maintenance
spec:
schedule: "0 2 * * 0"
operationTemplate:
spec:
pipeline:
- step: upgrade
functionRef:
name: function-database-upgrade
Operational workflows are now first-class API objects. Agents can inspect them, trigger them, observe their status, and propose modifications. No need for hidden runbooks.
Where to start
This doesn’t require a start-from-scratch migration. Bring core infrastructure under declarative control first. Your existing resources don’t need to be replaced; they just need to be unified behind a consistent API.
For teams using AI-assisted development, engineers express intent and iterate quickly as tools accelerate implementation. As deployment decouples from release, with changes shipping behind feature flags and systems reconciling toward the desired state, the platform must be deterministic and self-correcting, not reliant on someone catching drift or running the right command at the right time.
That is what a declarative control plane provides. Crossplane ensures that intent has somewhere safe, structured, and deterministic to land. Without it, AI will always be bolted onto human-centric workflows. With it, agents become first-class participants in infrastructure operations.
And that starts with a consistent API.
And that starts with a consistent API. Get started by checking out the Crossplane Docs, attending a community meeting, or watching CNCF’s Cloud Native Live on Crossplane 2.0 – AI-Driven Control Loops for Platform Engineering.