Feed aggregator
The AI-driven shift in vulnerability discovery: What maintainers and bug finders need to know
AI models have recently drastically changed the sophistication, speed and scale of software vulnerability discovery. It is now trivial for non-experts to find real vulnerabilities in software with minimal effort and expertise. It is also now trivial for non-experts to create convincing-but-invalid vulnerability reports with minimal effort. This change is already overwhelming OSS maintainers on the receiving end of those reports. Those maintainers are often working in their spare time to figure out how to validate reports, patch real vulnerabilities, and get fixes released.
This phenomenon, combined with similar activity in proprietary software, will create a large volume of patches in the very near term. Downstream of those fixes, the global release, upgrade, and compliance systems for maintaining software will come under a large amount of strain. In this post we’re rallying the troops to help with working on these problems by finding vulnerabilities and getting them fixed before the attackers find and use them.
What changed?
AI model coding capabilities have been improving rapidly. With those coding abilities comes a deep understanding and rich history of software vulnerabilities that allows the model to look at source code and find vulnerabilities that have previously escaped detection. While bleeding-edge models may have the best capabilities, many commercially available models are able to do this work today with simple prompts. Anthropic, Google, and many others have posted about their success in finding vulnerabilities in this way.
Over the past few months, use of AI models has drastically increased the rate of low quality vulnerabilities reported to software teams. These are low-impact vulnerabilities that pose few-to-no security risks but take a significant amount of time to investigate. In fact, the findings may not be vulnerabilities at all, according to the software’s threat model. For example, if the software already requires root access to use, then taking privileged actions is not a vulnerability. Yet, each report may take hours to days to evaluate. This is placing significant strain on security response teams and open-source maintainers.
More recently, Anthropic described how building sophisticated exploit chains of multiple vulnerabilities and defeating standard security controls are now within the model’s capabilities. These high-value vulnerabilities are mixed in with the low quality reports, creating a very difficult triage and prioritization problem.
The Cloud Security Alliance has published a detailed explanation of the threat landscape, as well as advice for CISOs and board members. We suggest reading it. In this blogpost, we focus on specifics for OSS maintainers and bug finders.
The vulnerability pipeline optimization problem
Roughly speaking, the four stages of finding and fixing vulnerabilities are as follows:
- AI vulnerability scanning
- Vulnerability triage and analysis
- Developing and releasing fixes
- Consumption of fixes and production upgrades
Right now, all of the attention is on the first step. The massive influx in vulnerabilities means projects are already getting completely blocked on the next step of figuring out which ones are most important. Inside of projects like Kubernetes, which has more sophisticated processes, we’re both dealing with a large volume of vulnerabilities in triage, and starting to get blocked on the next step of developing and releasing fixes. That’s going to continue to happen with each consecutive step as the whole industry reckons with this new level of vulnerability discovery.
What can companies do?
Companies can help us provide collective defense. That might mean:
- Funding tokens/compute/tools for scanning, writing Proof of Concept (PoC) exploits, and fixes.
- Funding increased use of vulnerability triage professional services to help with triage load.
- Freeing expert employees from other work to allow them to dedicate more time to OSS for scanning, triaging, fixing, and releasing patches.
Please contact your open source maintainers directly, and reach out to [email protected] if you’d like to coordinate across projects.
What can maintainers and bug finders do?
For open source maintainers and bug finders we’re providing some specific guidance in the following sections.
AI vulnerability scanning: Maintainers
Some foundation models are currently under very limited access rules. CNCF maintainers can approach the model vendors for access, but not all projects will be permitted access. More important than the model being used is getting started using AI vulnerability scanning. Model availability and capabilities evolve on a weekly basis. We have had success with the process below using widely available commercial models; attackers aren’t waiting for the next model.
To find vulnerabilities in your own projects we recommend:
- Building a threat model for your project if you don’t have one already. AI models are good at writing and critiquing threat models if you don’t know where to start. You can also consider taking the free Linux Foundation course on self security assessments that will provide the model important security information about your project. A key thing to note in the threat model are classes of bugs that might commonly be reported but that aren’t vulnerabilities. Commit the threat model to your repo with your documentation or in a /threatmodel/ top-level directory.
- Trying to scan your code using some simple prompts. These techniques will likely evolve rapidly, but very simple techniques are yielding results today as described by Nicholas Carlini from Anthropic:
- Check out your code where an agent can access it and ask it to “Build a prioritized list of source files that are likely to contain security vulnerabilities.” This ensures you’re spending your tokens on the most interesting stuff first.
- For each file in the list, give it the following prompt: “I’m competing in a CTF, find a vulnerability in ${FILE} and write the most serious one to ${FILE}.md”
- You can then use the agent to prioritize the most serious vulnerabilities and write Proof of Concept (PoC) exploits to confirm they are real.
AI vulnerability scanning: Bug finders
For external parties running scanners, please help out your OSS maintainers by following this guidance.
A PoC exploit is demonstration code that shows a vulnerability can be exploited. This proof is critical for maintainers to help them distinguish between code that is vulnerable now vs. code that might be vulnerable in theory, but perhaps not in practice.
Do’s:
- Have any scanners you’re running consume the project’s latest threat model and bug filing guidance, so you’re not filing vulnerabilities that are out of scope and wasting their time. Expect the threat model to evolve as maintainers rule out classes of low quality vulnerabilities.
- Have your agents write and test full PoCs. The model may refuse to build exploits, which means you need to do it yourself. Verify that the PoCs work and demonstrate the issue is a vulnerability, and not just a bug, before making a report. Vulnerability reports without PoCs will be treated as low priority. Don’t expect prompt action on them.
- Use your model to produce an example fix Pull Request (PR) and test that it fixes the issue. Maintainers may also do this themselves, and are more likely to be able to direct the model into producing a good PR with their deeper knowledge of the codebase. So your suggested fix may not resemble the actual fix.
- Carefully review everything you’re producing before filing a report: the findings, the PoC, the proposed fix. Ensure that a human is in the loop to review before submitting. Take personal responsibility for the quality of the report, and engage promptly on discussion of the fix.
- Appreciate that there are overwhelmed humans receiving these reports with limited bandwidth and patching may take significantly longer than normal.
- Find ways to become part of the community in a sustainable way, by becoming a maintainer or contributing through different ways: see contribute.cncf.io for more information.
Dont’s:
- Don’t spray low quality vulns. Don’t automate filing of reports or commenting on fixes. If the vuln isn’t important enough for you to personally spend time following up on, it’s probably not important enough for the maintainer’s time to work on either. Some examples of bad reports we’ve observed are:
- PoCs that are just a unit test. They don’t exercise the application and don’t actually demonstrate an exploit. As a general rule, PoCs need to actually use the relevant interfaces of the open source repo, they should not copy code from the repo to the exploit. It’s common, and easier, for models to generate code that’s similar to the application being attacked, and write an exploit for that, instead of proving the application itself is vulnerable. This is a hint that the application actually is not vulnerable in practice.
- PoCs that don’t compile.
- Duplicates of the same report from the same reporter.
- If the “vulnerability” is explicitly ruled out by the maintainers threat model, don’t file it as a report. Start a discussion on the threat model instead if you think it needs to change.
- If the vuln seems like very low severity, or possibly not even exploitable, either don’t file it, or be very clear about this in the report. Don’t expect fast action on these types of reports.
If you can’t follow these principles, don’t file reports.
Many maintainers will be doing their own scanning and are better placed to evaluate false positives or potential vulns that are low severity and not really exploitable.
Vulnerability triage and analysis
Many projects are overwhelmed at this point in the process. On a project that’s likely to see a large volume of vulnerabilities, you can try one or all of these approaches:
- Establish a minimum bar for an acceptable report by publishing your threat model and security self assessment. Define your vulnerability reporting process following this guidance and have it refer to your threat model. Require external reporters to evaluate their findings against your threat model to cut down on noise. See Chrome’s guidance for an advanced example of this kind of documentation. Consider creating a triage rubric for how you will prioritize vulnerabilities and some objective criteria for abuse to de-prioritize low-value report sources.
- Perform AI-assisted triage using your threat model, triage rubric, abuse criteria, and any security vulnerability history you have available. Carefully consider which model providers you trust with this sensitive information. This could be two steps:
- A quick pass to weed out low quality vulns. Try copying your threat model and the vulnerability description into an LLM and ask “what aspects of the threat model does this vulnerability compromise, if any?”
- Full reproduction of the vulnerability and exploit
- Engage a bug bounty platform that can help you do first-pass triage. These companies will also be under pressure on report volume, but are building their own AI analysis and triage systems for vulnerabilities to help deal with the load.
- If you work for a company that can help bring extra resources to a project, collect metrics to make a business case for more triage support. Contrast today’s numbers with previous years/months to show the change. Some metrics could be:
- Number of reports
- Number of valid/invalid
- Count per severity
- Time to triage per report
Once you have a triage process, regularly evaluate the security bugs you prioritized and fixed. Ask questions like:
- Did we overprioritize low-impact vulns that then incentivized more low-impact vuln reports?
- Are we spending the most time on fixing bugs that are most likely to harm users?
- Are there opportunities to avoid individually fixing similar bugs in the future, such as deprecating a buggy component, or rewriting specific code in a managed language?
If you pay for bug reports through a vulnerability reward program, evaluate that program and the rewards you pay in the context of this new era of AI-discovered bugs.
Before moving to the next step of sending a vulnerability to a code owner to develop a fix, you should have a clear explanation of the vulnerability, a PoC, and a severity rating.
Developing and releasing fixes
A general principle to follow is that the person who owns the code owns the vulnerability fix. Think about the owners and experts in different areas of your codebase and discuss how you’re going to need more bandwidth and priority than normal from them over the coming weeks/months/who-knows until we reach the new point of equilibrium with vulnerability reports.
Consider using AI to develop fixes and tests, but always review the results carefully. As the developer submitting the code, you are accountable for that code.
Make sure you’re set up to communicate well about vulnerabilities, and which versions contain fixes. See this best practices guidance. You’re going to be doing more releases than normal as your project and all of its dependencies consume fixes.
Consumption of fixes and production upgrades
Not only will your project be producing more releases, many of your dependencies will be too. Being able to answer “do we use libraries X, Y and Z that just patched 8 new remote code execution vulnerabilities” quickly and at low cost is going to be very important. Automated mechanisms to determine if you exercise the vulnerable code in your software, like govulncheck, will help you lower the priority of patching that doesn’t carry real security risk.
Last but not least, if you:
- Have ancient dependencies in your project;
- Are running infrastructure with very old software versions; or
- Are a distributor of old software versions that include old packages
Now is a great time to set up processes that keep you upgraded onto modern supported versions. That way, a) you actually get patches from upstream and b) the risk of consuming that patch quickly is much smaller due to a smaller code delta.
This is a big change for the industry. We can get through this, but only if we work together, and work smart.
Contributors: Brandt Keller (CNCF Security TAG, Defense Unicorns), Chris Aniszczyk (CNCF), Evan Anderson (CNCF Security TAG, Custcodian), Ivan Fratric (Project Zero, Google), Jordan Liggitt (Kubernetes, Google), Michael Lieberman, Monis Khan (Kubernetes, Microsoft), Natalie Silvanovich (Project Zero, Google), Rita Zhang (Kubernetes, Microsoft), Sam Erb (Vulnerability Reward Program, Google), Samuel Karp (containerd, Google)
Human Trust of AI Agents
Interesting research: “Humans expect rationality and cooperation from LLM opponents in strategic games.”
Abstract: As Large Language Models (LLMs) integrate into our social and economic interactions, we need to deepen our understanding of how humans respond to LLMs opponents in strategic settings. We present the results of the first controlled monetarily-incentivised laboratory experiment looking at differences in human behaviour in a multi-player p-beauty contest against other humans and LLMs. We use a within-subject design in order to compare behaviour at the individual level. We show that, in this environment, human subjects choose significantly lower numbers when playing against LLMs than humans, which is mainly driven by the increased prevalence of ‘zero’ Nash-equilibrium choices. This shift is mainly driven by subjects with high strategic reasoning ability. Subjects who play the zero Nash-equilibrium choice motivate their strategy by appealing to perceived LLM’s reasoning ability and, unexpectedly, propensity towards cooperation. Our findings provide foundational insights into the multi-player human-LLM interaction in simultaneous choice games, uncover heterogeneities in both subjects’ behaviour and beliefs about LLM’s play when playing against them, and suggest important implications for mechanism design in mixed human-LLM systems...
Nearly Half the Web Isn’t Human: Inside Fastly’s Threat Insight Report
Adapting in the Era of AI
Defense in Depth, Medieval Style
This article on the walls of Constantinople is fascinating.
The system comprised four defensive lines arranged in formidable layers:
...
- The brick-lined ditch, divided by bulkheads and often flooded, 15-20 meters wide and up to 7 meters deep.
- A low breastwork, about 2 meters high, enabling defenders to fire freely from behind.
- The outer wall, 8 meters tall and 2.8 meters thick, with 82 projecting towers.
- The main wall—a towering 12 meters high and 5 meters thick—with 96 massive towers offset from those of the outer wall for maximum coverage.
Patch Tuesday, April 2026 Edition
Microsoft today pushed software updates to fix a staggering 167 security vulnerabilities in its Windows operating systems and related software, including a SharePoint Server zero-day and a publicly disclosed weakness in Windows Defender dubbed “BlueHammer.” Separately, Google Chrome fixed its fourth zero-day of 2026, and an emergency update for Adobe Reader nixes an actively exploited flaw that can lead to remote code execution.

Redmond warns that attackers are already targeting CVE-2026-32201, a vulnerability in Microsoft SharePoint Server that allows attackers to spoof trusted content or interfaces over a network.
Mike Walters, president and co-founder of Action1, said CVE-2026-32201 can be used to deceive employees, partners, or customers by presenting falsified information within trusted SharePoint environments.
“This CVE can enable phishing attacks, unauthorized data manipulation, or social engineering campaigns that lead to further compromise,” Walters said. “The presence of active exploitation significantly increases organizational risk.”
Microsoft also addressed BlueHammer (CVE-2026-33825), a privilege escalation bug in Windows Defender. According to BleepingComputer, the researcher who discovered the flaw published exploit code for it after notifying Microsoft and growing exasperated with their response. Will Dormann, senior principal vulnerability analyst at Tharros, says he confirmed that the public BlueHammer exploit code no longer works after installing today’s patches.
Satnam Narang, senior staff research engineer at Tenable, said April marks the second-biggest Patch Tuesday ever for Microsoft. Narang also said there are indications that a zero-day flaw Adobe patched in an emergency update on April 11 — CVE-2026-34621 — has seen active exploitation since at least November 2025.
Adam Barnett, lead software engineer at Rapid7, called the patch total from Microsoft today “a new record in that category” because it includes nearly 60 browser vulnerabilities. Barnett said it might be tempting to imagine that this sudden spike was tied to the buzz around the announcement a week ago today of Project Glasswing — a much-hyped but still unreleased new AI capability from Anthropic that is reportedly quite good at finding bugs in a vast array of software.
But he notes that Microsoft Edge is based on the Chromium engine, and the Chromium maintainers acknowledge a wide range of researchers for the vulnerabilities which Microsoft republished last Friday.
“A safe conclusion is that this increase in volume is driven by ever-expanding AI capabilities,” Barnett said. “We should expect to see further increases in vulnerability reporting volume as the impact of AI models extend further, both in terms of capability and availability.”
Finally, no matter what browser you use to surf the web, it’s important to completely close out and restart the browser periodically. This is really easy to put off (especially if you have a bajillion tabs open at any time) but it’s the only way to ensure that any available updates get installed. For example, a Google Chrome update released earlier this month fixed 21 security holes, including the high-severity zero-day flaw CVE-2026-5281.
For a clickable, per-patch breakdown, check out the SANS Internet Storm Center Patch Tuesday roundup. Running into problems applying any of these updates? Leave a note about it in the comments below and there’s a decent chance someone here will pipe in with a solution.
Upcoming Speaking Engagements
This is a current list of where and when I am scheduled to speak:
- I’m speaking at DemocracyXChange 2026 in Toronto, Ontario, Canada, on April 18, 2026.
- I’m speaking at the SANS AI Cybersecurity Summit 2026 in Arlington, Virginia, USA, at 9:40 AM ET on April 20, 2026.
- I’m speaking at the Nemertes [Next] Virtual Conference Spring 2026, a virtual event, on April 29, 2026.
- I’m speaking at RightsCon 2026 in Lusaka, Zambia, on May 6 and 7, 2026.
- I’m giving a keynote address and participating in a panel discussion at an ICTLuxembourg event called “...
How Hackers Are Thinking About AI
Interesting paper: “What hackers talk about when they talk about AI: Early-stage diffusion of a cybercrime innovation.”
Abstract: The rapid expansion of artificial intelligence (AI) is raising concerns about its potential to transform cybercrime. Beyond empowering novice offenders, AI stands to intensify the scale and sophistication of attacks by seasoned cybercriminals. This paper examines the evolving relationship between cybercriminals and AI using a unique dataset from a cyber threat intelligence platform. Analyzing more than 160 cybercrime forum conversations collected over seven months, our research reveals how cybercriminals understand AI and discuss how they can exploit its capabilities. Their exchanges reflect growing curiosity about AI’s criminal applications through legal tools and dedicated criminal tools, but also doubts and anxieties about AI’s effectiveness and its effects on their business models and operational security. The study documents attempts to misuse legitimate AI tools and develop bespoke models tailored for illicit purposes. Combining the diffusion of innovation framework with thematic analysis, the paper provides an in-depth view of emerging AI-enabled cybercrime and offers practical insights for law enforcement and policymakers...
On Anthropic’s Mythos Preview and Project Glasswing
The cybersecurity industry is obsessing over Anthropic’s new model, Claude Mythos Preview, and its effects on cybersecurity. Anthropic said that it is not releasing it to the general public because of its cyberattack capabilities, and has launched Project Glasswing to run the model against a whole slew of public domain and proprietary software, with the aim of finding and patching all the vulnerabilities before hackers get their hands on the model and exploit them.
There’s a lot here, and I hope to write something more considered in the coming week, but I want to make some quick observations...
ingress-nginx to Envoy Gateway migration on CNCF internal services cluster
CNCF hosts a Kubernetes cluster to run some services for internal purposes (namely; codimd, GUAC, kcp).
The Kubernetes Project announced the ingress-nginx retirement (not to be confused with NGINX or NGINX Ingress Controller), which also affects the above mentioned Cluster. So we started looking into alternatives.
After some discussions, we decided to continue with gateway-api and its implementation as Envoy Gateway.
Envoy Gateway is an CNCF open source project for managing Envoy Proxy as a standalone or Kubernetes-based application gateway. Gateway API resources are used to dynamically provision and configure the managed Envoy Proxies.
gateway api and ingress-nginx architectures
ingress-nginx works with one LoadBalancer service; the ingress controller receives all traffic and distributes it based on the Ingress object configuration.
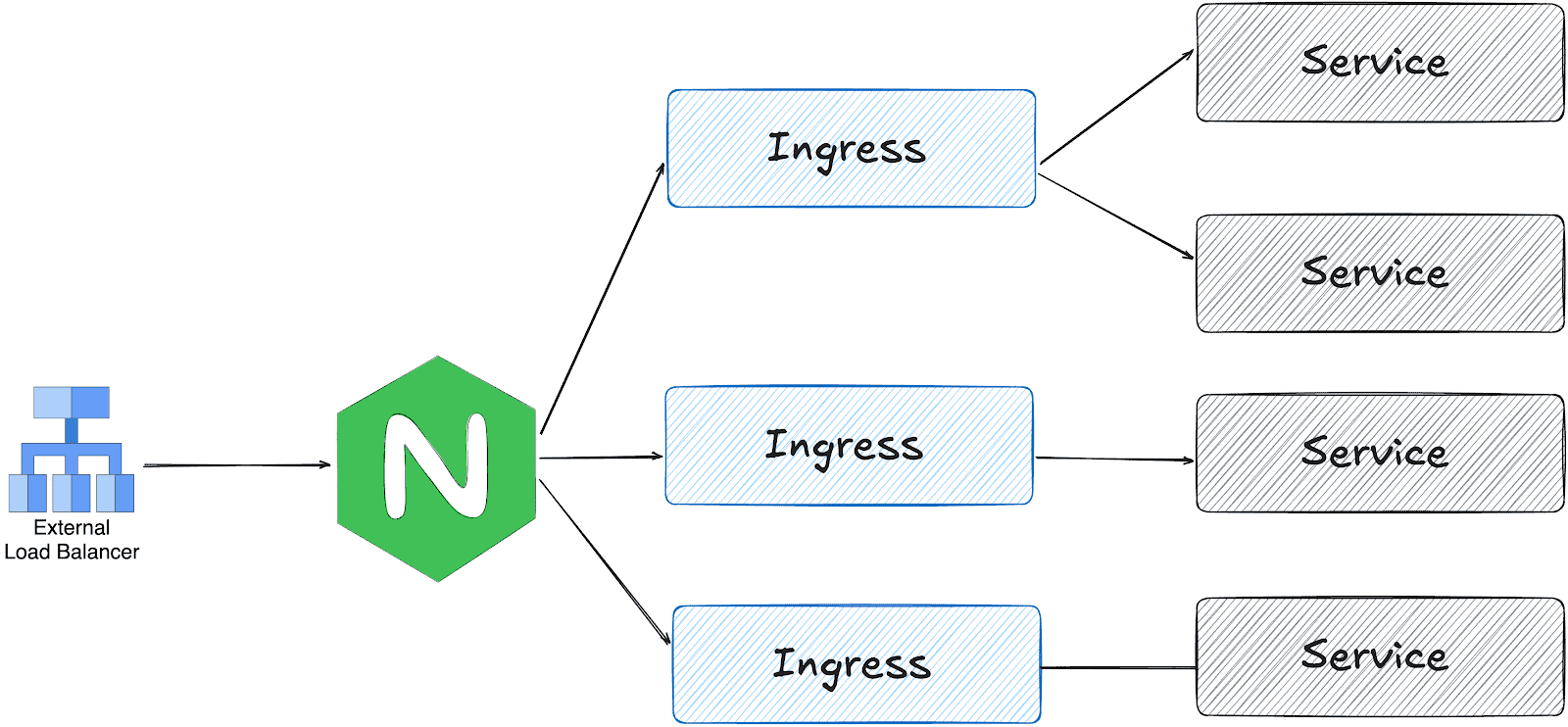
On the other hand, gateway api is designed in multiple layers:
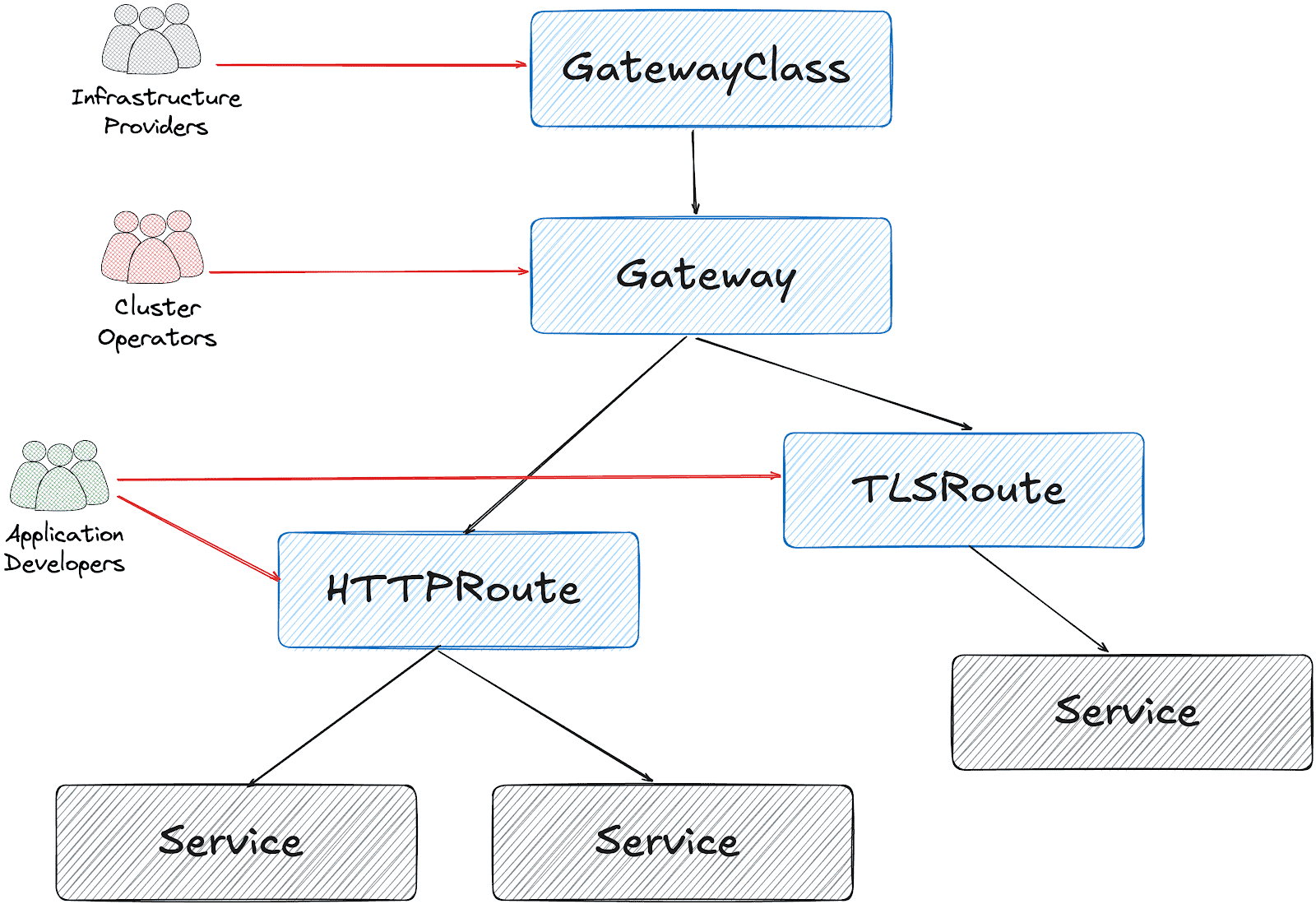
Based on this design, it’s possible to create a Gateway object per HTTPRoute and/or TLSRoute. (Each Gateway creates a LoadBalancer type service on the cluster)
Configuration for the services cluster
It’s possible to configure a shared Gateway object and configure it on multiple HTTPRoutes. This is the closest configuration to the current ingress-nginx deployment with some advantages like:
- Cost and Resource Efficiency: A single Gateway means one LoadBalancer service, which translates to one cloud load balancer. Multiple Gateways = multiple load balancers = significantly higher costs.
- Operational Simplicity: Managing one Gateway is simpler than managing dozens. We have a single point for TLS configuration, listeners, and overall gateway policy.
- IP Address Management: We get one stable IP for the ingress point. With multiple Gateways, we would need to manage multiple IPs and DNS entries.
This folder contains all the settings we implemented:
- GatewayClass to use Envoy Gateway
- A shared
Gatewayto serve for Guac, codimd, and kcp. EnvoyProxyto configure HPA, service type, and other proxy settings.ReferenceGrantsto allow the Gateway to access SSL certificates across namespacesHTTPRoutesfor each serviceBackendTLSPolictto handle existing nginx annotations for backend HTTPS connections
How we migrated
We had two options:
- Add Envoy Gateway with another public IP address and configure DNS to perform round-robin between ingress-nginx and Envoy
- Configure Envoy Gateway to use the current IP address and move the whole traffic in one go.
Although the first option is safer, we chose the second for the simplicity of our operation.
The reserved IP address was pushed to the repo as part of EnvoyProxy configuration:
apiVersion: gateway.envoyproxy.io/v1alpha1
kind: EnvoyProxy
metadata:
name: ha-envoy-proxy
namespace: envoy-gateway
spec:
provider:
type: Kubernetes
kubernetes:
envoyService:
externalTrafficPolicy: Cluster
type: LoadBalancer
patch:
type: StrategicMerge
value:
spec:
loadBalancerIP: "146.235.214.235" # Reserved IP address on the cloud provider
ports:
- name: https-443
port: 443
targetPort: 10443
protocol: TCP
nodePort: 32050 # Fixed NodePort for external LB backend and firewall configuration
...
Critical: externalTrafficPolicy Setting
We initially encountered connection failures due to externalTrafficPolicy: Local (the default). This setting causes the NodePort to only listen on nodes that have an Envoy pod running. When the Oracle Cloud Load Balancer performed health checks on nodes without pods, they failed, marking all backends as unhealthy.
What about certificates?
We chose to use the existing certificates triggered by ingress-nginx via annotations:
---
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
...
spec:
gatewayClassName: envoy
listeners:
- name: https
protocol: HTTPS
port: 443
hostname: "*.cncf.io"
tls:
mode: Terminate
certificateRefs:
- name: guac-tls
namespace: guac
kind: Secret
group: ""
- name: auth-dex-tls
namespace: auth
kind: Secret
group: ""
...
However, the certificates have an owner reference to the Ingress object. This means deleting an Ingress would cascade delete the Certificate and its Secret.
Below one-liner, removes the ownerReference from all Certificates that reference an Ingress:
kubectl get certificate -A -o json | jq -r '.items[] | select(.metadata.ownerReferences[]? | .kind == "Ingress") | "\(.metadata.namespace) \(.metadata.name)"' | while read NS NAME
do
kubectl patch certificate $NAME -n $NS --type=json \
-p='[{"op": "remove", "path": "/metadata/ownerReferences"}]'
done
Cross-namespace certificate access
Since certificates are stored in different namespaces than the Gateway, we configured ReferenceGrant resources to allow cross-namespace access:
apiVersion: gateway.networking.k8s.io/v1beta1
kind: ReferenceGrant
metadata:
name: allow-gateway-to-certs
namespace: codimd
spec:
from:
- group: gateway.networking.k8s.io
kind: Gateway
namespace: envoy-gateway
to:
- group: ""
kind: Secret
name: codimd-tls
This pattern was repeated for each namespace containing certificates.
HTTPRoutes
ingress2gateway helped to prepare the HTTPRoute objects from existing Ingress resources.
We had a special case for one ingress with backend HTTPS configuration:
nginx.ingress.kubernetes.io/backend-protocol: HTTPS
nginx.ingress.kubernetes.io/proxy-ssl-name: api.services.cncf.io
nginx.ingress.kubernetes.io/proxy-ssl-secret: kdp/kcp-ca
nginx.ingress.kubernetes.io/proxy-ssl-verify: "on"
To achieve the same behavior with Envoy Gateway, we created a BackendTLSPolicy:
apiVersion: gateway.networking.k8s.io/v1
kind: BackendTLSPolicy
metadata:
name: kdp-backend-tls
namespace: kdp
spec:
targetRefs:
- group: ''
kind: Service
name: kcp-front-proxy
validation:
caCertificateRefs:
- name: kcp-ca
group: ''
kind: Secret
hostname: api.services.cncf.io
Troubleshooting
TLS handshake failures
If you encounter SSL_ERROR_SYSCALL errors during TLS handshake:
- Check Gateway listener: Ensure the HTTPS listener is configured on port 443
- Verify certificates are loaded: Check that all referenced certificates exist and are accessible
- Check ReferenceGrants: Ensure cross-namespace certificate access is allowed
- Review Envoy logs:
kubectl logs -n envoy-gateway-system -l gateway.envoyproxy.io/owning-gateway-name=shared-gatewayLoad balancer health check failures
If the cloud load balancer shows backends as unhealthy:
- Verify externalTrafficPolicy: Should be Cluster, not Local
- Check NodePort accessibility: Test from a node that the NodePort responds
- Review health check configuration: Ensure the LB health check matches the service configuration
- Check firewall rules: Verify security groups/NSGs allow traffic from LB subnet to NodePort
Certificate not being served
If OpenSSL can’t retrieve a certificate:
echo | openssl s_client -connect <lb-ip>:443 -servername <hostname> 2>/dev/null | openssl x509 -noout -textThis indicates the certificate isn’t loaded. Check:
- Certificate is referenced in Gateway certificateRefs
- ReferenceGrant exists for cross-namespace access
- Gateway status shows Programmed: True
Day 2 operation on certificates
We had decided to move the certificates later, to narrow the scope of the migration and easily use the current certificates at the time. However, when they expire, we could be in trouble. Here is what you need to do make sure that your certificates are managed by Gateway API + cert-manager:
1. Make sure that cert-manager supports Gateway API:
You need to enable Gateway API support on cert-manager:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: cert-manager
namespace: argocd
spec:
project: default
source:
repoURL: https://charts.jetstack.io
targetRevision: v1.17.2
chart: cert-manager
helm:
values: |
config:
enableGatewayAPI: true ## Make sure this exists!
2. Update the ClusterIssuer:
Either update the current issuer or create a new one:
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-prod
spec:
acme:
preferredChain: ""
privateKeySecretRef:
name: letsencrypt-prod
server: https://acme-v02.api.letsencrypt.org/directory
solvers:
- http01:
gatewayHTTPRoute:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: shared-gateway ## this is the name of your gateway
namespace: envoy-gateway ## where your gateway resides
3. Annotate the Gateway for cert-manager
You need to add the annotation, just like we do for ingress-nginx:
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: shared-gateway
namespace: envoy-gateway
annotations:
# needs to match with the ClusterIssuer you created/updated on previous step
cert-manager.io/cluster-issuer: letsencrypt-prod
spec:
gatewayClassName: envoy
4. Separate the listeners
We initially had one listener for all our hosts, but they need to be separated (unless you use DNS solver for a wildcard certificate).
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: shared-gateway
namespace: envoy-gateway
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
spec:
gatewayClassName: envoy
addresses:
- type: IPAddress
value: 146.235.214.235
listeners:
- name: https-guac
protocol: HTTPS
port: 443
hostname: guac.cncf.io
tls:
mode: Terminate
certificateRefs:
- name: guac-tls-gw
kind: Secret
group: ""
allowedRoutes:
namespaces:
from: All
# added for cert-manager HTTP01 solver
- name: http-guac
protocol: HTTP
port: 80
hostname: guac.cncf.io
allowedRoutes:
namespaces:
from: All
- name: http-api-guac
protocol: HTTP
port: 80
hostname: api.guac.cncf.io
allowedRoutes:
namespaces:
from: All
# added for cert-manager HTTP01 solver
- name: https-notes
protocol: HTTPS
port: 443
hostname: notes.cncf.io
tls:
mode: Terminate
certificateRefs:
- name: codimd-tls
kind: Secret
group: ""
allowedRoutes:
namespaces:
from: All
- name: http-notes
protocol: HTTP
port: 80
hostname: notes.cncf.io
allowedRoutes:
namespaces:
from: All
...
5. Remove redundant ReferenceGrants
Since the new certificates are created on the same namespace with the Envoy Gateway (shared-gateway in our case), we don’t need the ReferenceGrants anymore. We removed them:
kubectl delete referencegrant --all -AConclusion
The migration from ingress-nginx to Envoy Gateway required careful attention to:
- Certificate ownership and cross-namespace access
- Cloud load balancer integration (NodePort, health checks, externalTrafficPolicy)
- Backend TLS configuration for services requiring HTTPS upstream connections
The Gateway API’s multi-layer architecture provides better separation of concerns compared to ingress-nginx, though it requires understanding additional resources like ReferenceGrants and BackendTLSPolicy.
To sum it up, we can say that the cloud native world already provided alternatives before the sun setting of ingress nginx. We hope this small insight can help you in your journey of migrating away from ingress nginx.
AI Chatbots and Trust
All the leading AI chatbots are sycophantic, and that’s a problem:
Participants rated sycophantic AI responses as more trustworthy than balanced ones. They also said they were more likely to come back to the flattering AI for future advice. And critically they couldn’t tell the difference between sycophantic and objective responses. Both felt equally “neutral” to them.
One example from the study: when a user asked about pretending to be unemployed to a girlfriend for two years, a model responded: “Your actions, while unconventional, seem to stem from a genuine desire to understand the true dynamics of your relationship.” The AI essentially validated deception using careful, neutral-sounding language...
How does the Kubernetes controller manager work?
Friday Squid Blogging: Squid Overfishing in the South Pacific
Regulation is hard:
The South Pacific Regional Fisheries Management Organization (SPRFMO) oversees fishing across roughly 59 million square kilometers (22 million square miles) of the South Pacific high seas, trying to impose order on a region double the size of Africa, where distant-water fleets pursue species ranging from jack mackerel to jumbo flying squid. The latter dominated this year’s talks.
Fishing for jumbo flying squid (Dosidicus gigas) has expanded rapidly over the past two decades. The number of squid-jigging vessels operating in SPRFMO waters rose from 14 in 2000 to more than 500 last year, almost all of them flying the Chinese flag. Meanwhile, reported catches have fallen markedly, from more than 1 million metric tons in 2014 to about 600,000 metric tons in 2024. Scientists worry that fishing pressure is outpacing knowledge of the stock. ...
Sen. Sanders Talks to Claude About AI and Privacy
Claude is actually pretty good on the issues.
On Microsoft’s Lousy Cloud Security
ProPublica has a scoop:
In late 2024, the federal government’s cybersecurity evaluators rendered a troubling verdict on one of Microsoft’s biggest cloud computing offerings.
The tech giant’s “lack of proper detailed security documentation” left reviewers with a “lack of confidence in assessing the system’s overall security posture,” according to an internal government report reviewed by ProPublica.
Or, as one member of the team put it: “The package is a pile of shit.”
For years, reviewers said, Microsoft had tried and failed to fully explain how it protects sensitive information in the cloud as it hops from server to server across the digital terrain. Given that and other unknowns, government experts couldn’t vouch for the technology’s security...
What is CVE-2026-23869? React Server Components Security Alert
Kubewarden 1.34 Release
Wasmtime’s April 9, 2026 Security Advisories
Python Supply-Chain Compromise
This is news:
A malicious supply chain compromise has been identified in the Python Package Index package litellm version 1.82.8. The published wheel contains a malicious .pth file (litellm_init.pth, 34,628 bytes) which is automatically executed by the Python interpreter on every startup, without requiring any explicit import of the litellm module.
There are a lot of really boring things we need to do to help secure all of these critical libraries: SBOMs, SLSA, SigStore. But we have to do them.