Rook Blog

Running Rook at Petabyte Scale Across Multiple Regions
This post describes how SAP’s cloud infrastructure team uses Rook to manage a multi-region Ceph fleet — from bare metal provisioning to rolling upgrades — as part of building a digitally sovereign storage backbone for Europe.
The 120 Petabyte Challenge
When you are responsible for a target of 120 Petabytes of storage across 30 Regions, manual operations don’t scale.
For years, SAP Cloud Infrastructure relied on a mix of proprietary appliances and legacy OpenStack Swift. But as we architected our next-generation cloud stack (internally part of the Apeiro project), we faced a non-negotiable constraint: Digital Sovereignty. Our stack had to be completely free of hyperscaler lock-in, running on our own hardware in our own data centers.
This created a concrete engineering challenge: build a storage layer that is API-first, fully open-source, and capable of self-management at a global scale. We chose Ceph for the storage engine — and Rook for the automation layer that makes it manageable.
Why Rook
Managing Ceph at this scale without an operator would mean building and maintaining custom tooling for OSD lifecycle, daemon placement, upgrade orchestration, and failure recovery across every region. Rook gives us all of this as a declarative Kubernetes-native interface, which means our existing GitOps and CI/CD workflows extend naturally to storage. Instead of writing region-specific runbooks, we write Helm values.
Architecture: The Separation of Metal and Software
Our platform, CobaltCore, is built on top of Gardener and Metal-API both part of the ApeiroRA reference architecture. In this stack, storage isn’t a static resource — it’s a programmable Kubernetes object. We run storage on dedicated nodes, separate from application workloads. At our density (16 NVMe drives per node), co-locating workloads would create unacceptable I/O interference, so storage nodes do one thing: serve data.
The Metal Layer
Metal-API and Gardener manage the physical lifecycle of bare-metal servers: inventory, provisioning, firmware, and OS deployment. This allows Rook to focus purely on the software layer without worrying about the underlying physical state.
The Declarative Storage Layer (Rook)
Once nodes are handed over, Rook takes control. We use a strict GitOps workflow to ensure consistency across the fleet:
- Base Blueprint: A central Helm chart defines global best practices and standard Ceph configurations.
- Region Overlay: Region-specific resources (CephBlockPools, RGW placement rules) are injected via localized values.yaml files.
- Automation: Rook handles the rest: bootstrapping daemons, configuring CRUSH failure domains, and provisioning RGW endpoints.
Standard Storage Node Spec:
- Server: Dell PowerEdge R7615
- CPU: AMD EPYC 9554P (64 cores)
- RAM: 384 GB
- Storage: 16x 14 TB NVMe
- Network: 100 GbE (redundant)
Validation: Establishing the Performance Envelope
Before committing to production capacity planning, we needed to establish the performance envelope of our RGW tier. We ran a breakpoint test on a typical Ceph Squid cluster (28 nodes, 362 OSDs) to find the stable operating range, saturation threshold, and hard ceiling.
Test Setup
- Workload: 2M objects (4 KB each), 20 k6 clients, single “premium” NVMe bucket.
- Method: Ramping load over 30 minutes until p90 latency exceeded 500 ms.
Results
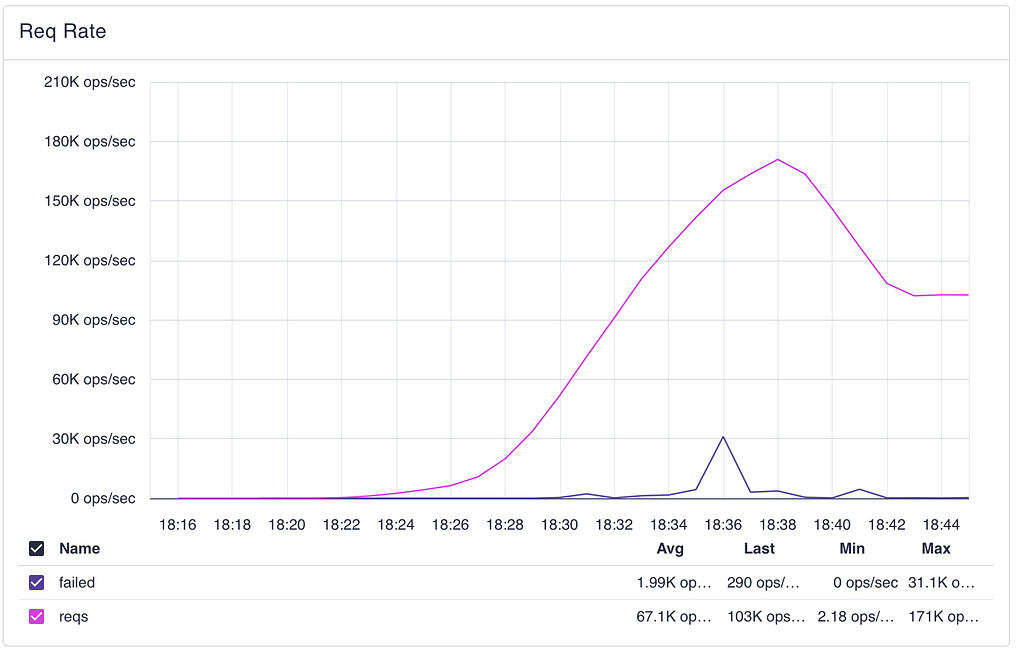 Request rate ramp: successful requests (pink) peak at 171K ops/sec before the test exits. Failed requests (blue) spike briefly near saturation.
Request rate ramp: successful requests (pink) peak at 171K ops/sec before the test exits. Failed requests (blue) spike briefly near saturation.- Saturation Point: The cluster entered saturation around 90K GET/s — latency percentiles begin diverging and request queues start building.
- Breaking Point: Peak of 171K GET/s (measured on RGW) before the runners hit the latency exit condition.
Note: isolated 503s appeared as early as ~33K GET/s on a single RGW instance, likely caused by uneven load distribution rather than cluster-wide saturation.
Reading the charts
 Client-side latency (k6): flat near zero through moderate load, stepping up as the cluster approaches saturation, and reaching 1.5s+ at the breaking point.
Client-side latency (k6): flat near zero through moderate load, stepping up as the cluster approaches saturation, and reaching 1.5s+ at the breaking point.The client-side latency chart tells the story most directly. Average request duration stays flat near zero well into the ramp — then steps up sharply as the cluster enters saturation and eventually hits its ceiling.
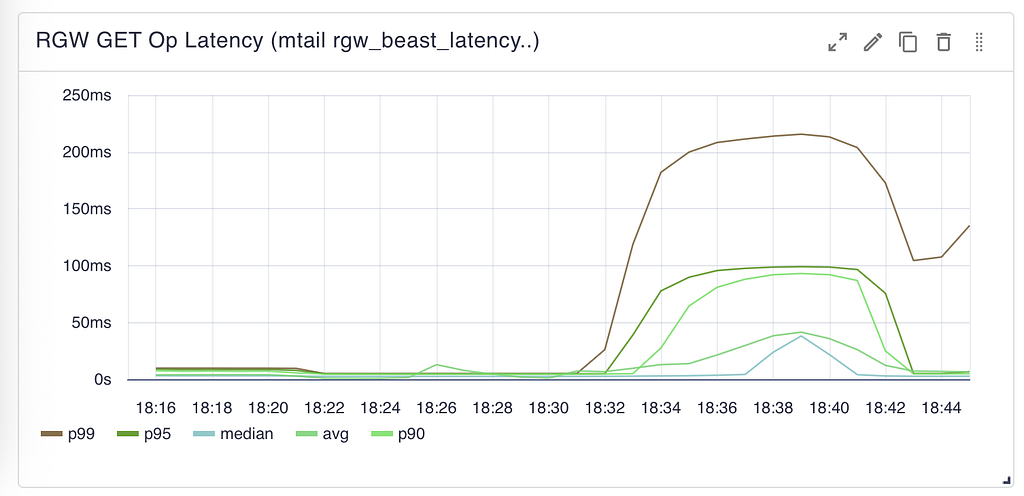 RGW-side GET latency: all percentiles stay flat and sub-ms through moderate load. Around 90K GET/s, p99 begins climbing while median remains low — a classic saturation signal.
RGW-side GET latency: all percentiles stay flat and sub-ms through moderate load. Around 90K GET/s, p99 begins climbing while median remains low — a classic saturation signal.Comparing the two charts reveals where the system saturates. At peak load, RGW reports p99 latency of ~210ms — but clients observe 1.5 seconds. The gap is connection queueing: requests waiting to be picked up by RGW Beast frontend threads. RGW’s internal metrics only measure processing time after a request is accepted, not time spent in the queue.
The RGW latency chart also shows that RADOS operation latency climbs under load, which means RGW threads stay occupied longer, contributing to the queue buildup. At the breaking point, request queues filled and RGWs began returning 503s across all instances.
This is a read-focused baseline — our primary workload is read-heavy. The saturation point of 90K GET/s gives us a conservative operating ceiling for per-region capacity planning.
Operational Reality: Making Day 2 Uneventful
The true test of any storage system is what happens when things break or need upgrading. At our scale, the goal is to make operations boring.
Zero-Downtime Upgrades
Rook has reduced storage maintenance from a coordinated event to a background task. Since the first cluster went live in May 2024, we have maintained a continuous upgrade cadence with zero customer-facing downtime and zero data loss:
- GardenLinux: Monthly rolling updates across all regions.
- Kubernetes: Quarterly version upgrades.
- Rook: Quarterly upgrades (v1.14 through v1.18), with additional upgrades when a needed feature ships in a new release.
- Ceph: Major version migration from Reef v18 to Squid v19. A rolling upgrade of the largest cluster (~816 OSDs) completes in approximately 2 days.
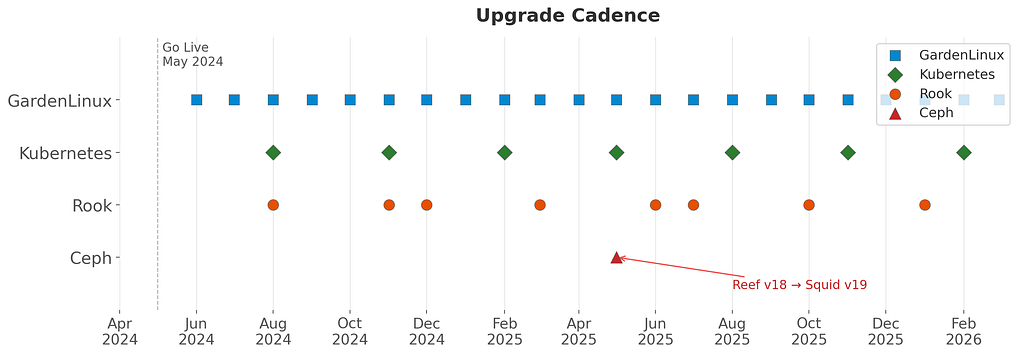 Upgrade cadence since May 2024: GardenLinux monthly, Kubernetes quarterly, Rook quarterly (with extra upgrades for needed features), and one Ceph major version migration.
Upgrade cadence since May 2024: GardenLinux monthly, Kubernetes quarterly, Rook quarterly (with extra upgrades for needed features), and one Ceph major version migration.Drive Failures
With ~2,800 OSDs in the fleet, drive failures are a routine event. When a drive fails, Ceph (RADOS) automatically handles data recovery and rebalancing across the remaining OSDs — no operator action is needed to protect data. On the Kubernetes side, Rook detects the failed OSD pod and manages its lifecycle. The full drive replacement cycle (removing the failed OSD, clearing the device, provisioning a new OSD on the replacement drive) still involves operational steps on our side, but Ceph’s self-healing ensures data durability is never at risk while the replacement is carried out.
Current Status and What’s Next
As of early 2026, the fleet spans 10 live regions (with an 11th newly provisioned):
- Storage Nodes: 251
- Total OSDs: ~2,800
- Raw Capacity: ~37 PiB
Region sizes range from 13-node / 96-OSD deployments to 59-node / 816-OSD clusters — the same Rook-based GitOps workflow handles both.
The next phase is bringing high-performance Block Storage (RBD) into this declarative model to fully retire our remaining proprietary SANs.
- Target: 30 Regions.
- Target Capacity: 120 PB.
We are active contributors to the Rook project and continue collaborating with the maintainers as we scale toward these targets. The Rook Slack community has been a valuable resource throughout this journey.
This work is part of ApeiroRA — an open initiative developing a reference blueprint for sovereign cloud-edge infrastructure. All components use enterprise-friendly open-source licenses under neutral community governance. ApeiroRA welcomes participants — whether you want to adopt the blueprints, contribute components, or shape the architecture. Get started at the documentation portal.
Authors: SAP Engineering Team, CLYSO Engineering Team.
Running Rook at Petabyte Scale Across Multiple Regions was originally published in Rook Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.