Feed aggregator
Is AI Good for Democracy?
Politicians fixate on the global race for technological supremacy between US and China. They debate geopolitical implications of chip exports, latest model releases from each country, and military applications of AI. Someday, they believe, we might see advancements in AI tip the scales in a superpower conflict.
But the most important arms race of the 21st century is already happening elsewhere and, while AI is definitely the weapon of choice, combatants are distributed across dozens of domains.
Academic journals are flooded with AI-generated papers, and are turning to AI to help review submissions. Brazil’s ...
Making Harbor production-ready: Essential considerations for deployment
Harbor is an open-source container registry that secures artifacts with policies and role-based access control, ensuring images are scanned for vulnerabilities and signed as trusted. To learn more about Harbor and how to deploy it on a Virtual Machine (VM) and in Kubernetes (K8s), refer to parts 1 and 2 of the series.
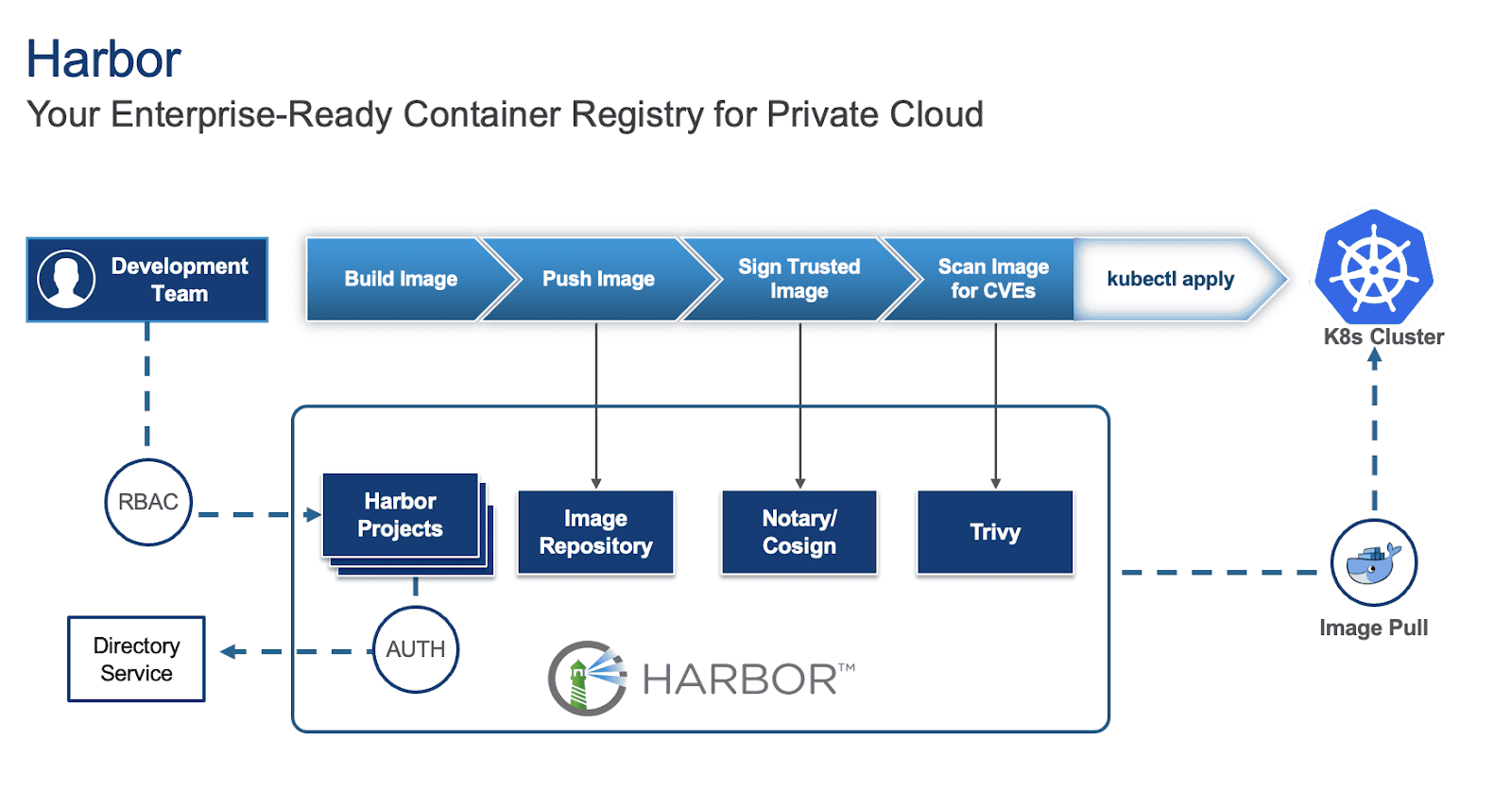
While deploying Harbor is straightforward, making it production-ready requires careful consideration of several key aspects. This blog outlines critical factors to ensure your Harbor instance is robust, secure, and scalable for production environments.
For this blog, we will focus on Harbor deployed on Kubernetes via Helm as our base and provide suggestions for this specific deployment.
1. High Availability (HA) and scalability
For a production environment, single points of failure are unacceptable, especially for an image registry that will act as a central repository for storing and pulling images and artifacts for development and production applications. Thus, implementing high availability for Harbor is crucial and involves several key considerations:
- Deploy with an Ingress: Configure a Kubernetes Service of type Ingress controller (e.g. Traefik) in front of your Harbor instances to distribute incoming traffic efficiently and provide a unified entry point along with cert-manager for certificate management. You can specify this in your values.yaml file under:
expose:
type: ingress
tls:
enabled: true
certSource: secret
ingress:
hosts:
core: harbor.yourdomain.com
annotations:
# Specify your ingress class
kubernetes.io/ingress.class: traefik
# Reference your ClusterIssuer (e.g., self-signed or internal CA)
cert-manager.io/cluster-issuer: "harbor-cluster-issuer"
To locate your values.yaml file, refer to the previous blog.
- Utilize multiple Harbor instances: Increase the replica count for critical Harbor components (e.g., core, jobservice, portal, registry, trivy) in your values.yaml to ensure redundancy.
core:
replicas: 3
jobservice:
replicas: 3
portal:
replicas: 3
registry:
replicas: 3
trivy:
replicas: 3
# While not strictly for the HA of the registry itself, consider increasing exporter replicas for robust monitoring availability
exporter:
replicas: 3
# Optionally, if using Ingress, consider increasing the Nginx replicas for improving Ingress availability
nginx:
replicas: 3
Configure shared storage: For persistent data, configure Kubernetes StorageClasses and PersistentVolumes to use shared storage solutions like vSAN or a distributed file system. Specify these in your values.yaml under:
persistence:
enabled: true
resourcePolicy: "keep"
persistentVolumeClaim:
registry:
#If left empty, the kubernetes cluster default storage class will be used
storageClass: "your-storage-class"
jobservice:
storageClass: "your-storage-class"
database:
storageClass: "your-storage-class"
redis:
storageClass: "your-storage-class"
trivy:
storageClass: "your-storage-class"
- Enable database HA (PostgreSQL): While Harbor comes with a built-in PostgreSQL database, it is not recommended for production use as it:
- Lack of high availability (HA): The default internal PostgreSQL setup within the Harbor Helm chart is typically a single instance. This creates a single point of failure. If that database pod goes down, your entire Harbor instance will be unavailable.
- Limited scalability: An embedded database is not designed for independent scaling. If your Harbor usage grows, you might hit database performance bottlenecks that are difficult to address without disrupting Harbor itself.
- Complex lifecycle management: Managing backups, point-in-time recovery, patching, and upgrades for a stateful database directly within an application’s Helm chart can be significantly more complex and error-prone than with dedicated database solutions.
Thus, it is recommended to deploy a highly available PostgreSQL cluster within Kubernetes (e.g., using a Helm chart for Patroni or CloudNativePG) or leverage a managed database service outside the cluster. Configure Harbor to connect to this HA database by updating the values.yaml:
database:
type: "external"
external:
host: "192.168.0.1"
port: "5432"
username: "user"
password: "password"
coreDatabase: "registry"
# If using an existing secret, the key must be "password"
existingSecret: ""
# "disable" - No SSL
# "require" - Always SSL (skip verification)
# "verify-ca" - Always SSL (verify that the certificate presented by the
# server was signed by a trusted CA)
# "verify-full" - Always SSL (verify that the certification presented by the
# server was signed by a trusted CA and the server host name matches the one
# in the certificate)
sslmode: "verify-full"
Implement Redis HA: Deploy a highly available Redis cluster in Kubernetes (e.g., using a Helm chart for Redis Sentinel or Redis Cluster) or utilize a managed Redis service. Configure Harbor to connect to this HA Redis instance by updating redis.type and connection details in values.yaml.
redis:
type: external
external:
addr: "192.168.0.2:6397"
sentinelMasterSet: ""
tlsOptions:
enable: true
username: ""
password: ""
2. Security best practices
Security is paramount for any production system, especially a container registry.
Enable TLS/SSL: Always enable TLS/SSL for all Harbor components.
expose:
tls:
enabled: true
certSource: auto # change to manual if using cert-manager
auto:
commonName: ""
internalTLS:
enabled: true
strong_ssl_ciphers: true
certSource: "auto"
core:
secretName: ""
jobService:
secretName: ""
registry:
secretName: ""
portal:
secretName: ""
trivy:
secretName: ""
Configure authentication and authorization: Leverage Harbor’s supported Authentication and Authorization mechanisms for managing access to Harbor resources. After Harbor deployment, integrate Harbor with enterprise identity providers like LDAP or OIDC by following the Harbor configuration guides: Configure LDAP/Active Directory Authentication or Configure OIDC Provider Authentication.
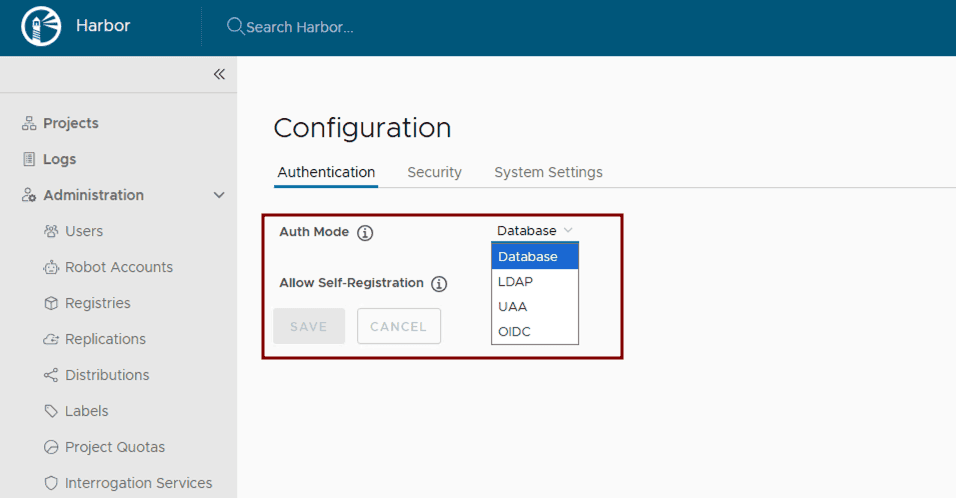
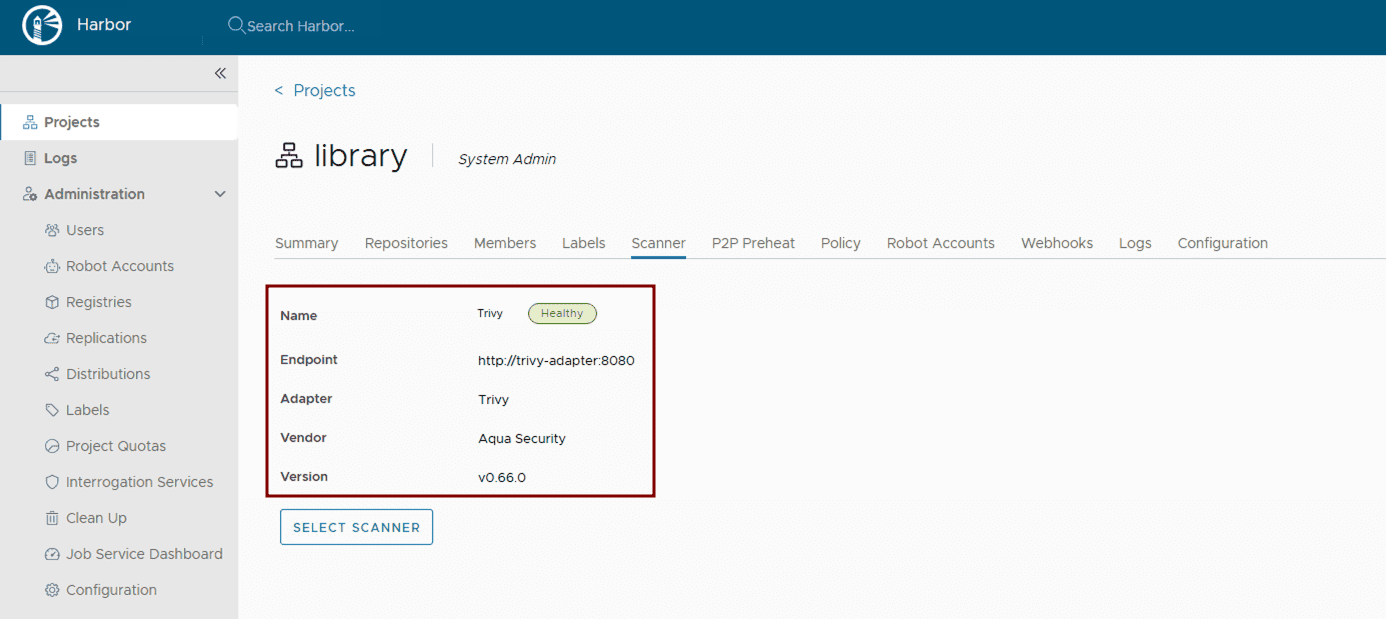
Implement vulnerability scanning: Ensure vulnerability scanning is enabled in values.yaml. Harbor uses Trivy by default. Verify its activation and configuration within the Helm chart.
trivy:
enabled: true
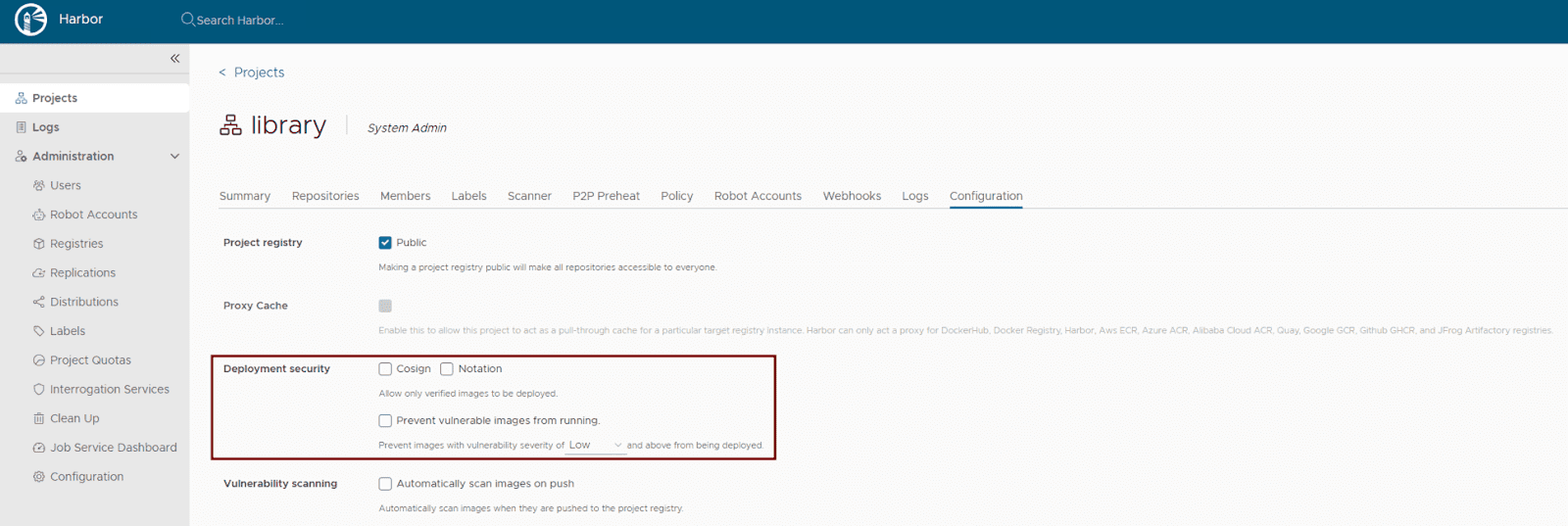
Activate content trust: Harbor supports multiple content trust mechanisms to ensure the integrity of your artifacts. For modern OCI artifact signing, Cosign and Notation are recommended. Enforce deployment security at the project level within the Harbor UI or via the Harbor API to allow only verified images to be deployed. This ensures that only trusted and cryptographically signed images can be deployed.
- Maintain regular updates: Regularly update your Harbor Helm chart and underlying Kubernetes components to benefit from the latest security patches and bug fixes. Use helm upgrade for this purpose.
- Use robot accounts for automation: Use robot accounts (service accounts) in automation such as CI/CD pipelines to avoid using user credentials. This ensures the robot account with the least required privileges is used to perform the specific task it has been created for, ensuring limited scope.
- Fine grained audit log: In Harbor v2.13.0, Harbor supports the re-direction of specific events in the audit log. For example, an “authentication failure” event can be configured in the audit log and forwarded to a 3rd party syslog endpoint.
3. Storage considerations
Efficient and reliable storage is critical for Harbor’s performance and stability.
- Choose appropriate storage type: Define Kubernetes StorageClasses that align with your underlying infrastructure (e.g., nfs-client, aws-ebs, azure-disk, gcp-pd). Specify these settings in your values.yaml:
persistence:
enabled: true
resourcePolicy: "keep"
imageChartStorage:
#Specify storage type: "filesystem", "azure", "gcs", "s3", "swift", "oss"
type: ""
#Configure specific storage type section based on the selected option
- Estimate storage sizing: Carefully calculate your storage needs based on the anticipated number and size of container images, as well as your defined retention policies. Configure the size for your PersistentVolumeClaims in values.yaml.
- Implement robust backup and recovery: Establish a comprehensive backup strategy for all Harbor data. For Kubernetes-native backups, consider using tools like Velero to back up PersistentVolumes and Kubernetes resources. For object storage, leverage the cloud provider’s backup mechanisms or external backup solutions. Regularly test your recovery procedures.
- Configure and run garbage collection: Set up and routinely execute Harbor’s garbage collection. This can be configured through the Harbor UI by defining a schedule for automated runs to remove unused blobs and efficiently reclaim storage space.
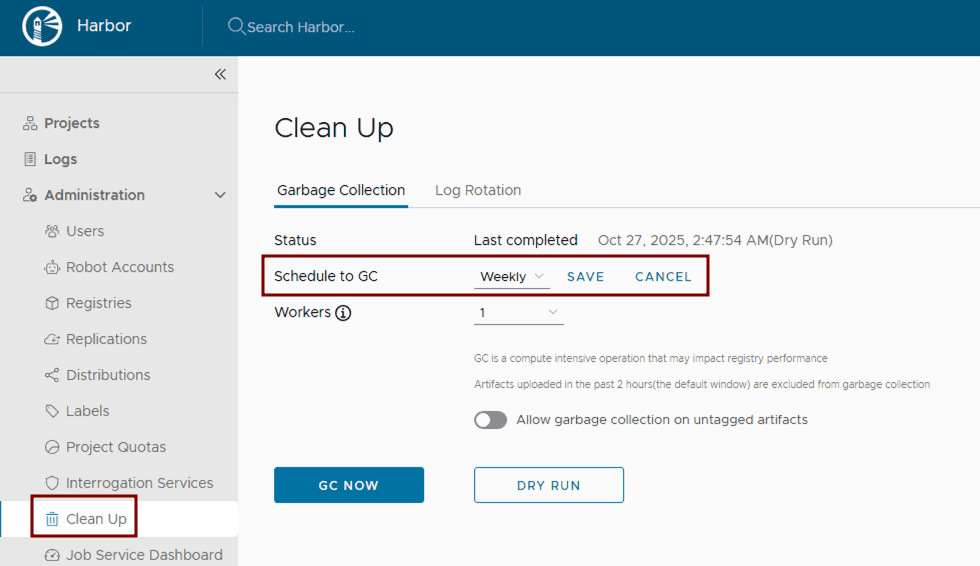
4. Monitoring and alerting
Proactive monitoring and alerting are essential for identifying and addressing issues before they impact users.
Collect Comprehensive Metrics: Deploy Prometheus and configure it to scrape metrics from Harbor components. The Harbor Helm chart exposes Prometheus-compatible endpoints in the values.yaml file. Visualize these metrics using Grafana.
metrics:
enabled: true
core:
path: /metrics
port: 8001
registry:
path: /metrics
port: 8001
jobservice:
path: /metrics
port: 8001
exporter:
path: /metrics
port: 8001
serviceMonitor:
enabled: true
# This label ensures the prometheus operator picks up these monitors
additionalLabels:
release: kube-prometheus-stack
# Example Service Monitor objects:
# Harbor Core (API and Auth Performance)
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: harbor-core
labels:
app: harbor
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: harbor
component: core
endpoints:
- port: metrics # Defaults to 8001
path: /metrics
interval: 30s
# Harbor Exporter (Business Metrics)
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: harbor-exporter
labels:
app: harbor
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: harbor
component: exporter
endpoints:
- port: metrics
path: /metrics
interval: 60s # Scraped less frequently as these are high-level stats
- Centralized logging: Implement a centralized logging solution within Kubernetes, such as the ELK stack (Elasticsearch, Logstash, Kibana) or Grafana with Fluentd/Fluent Bit.
- Configure critical alerts: Set up alerting rules in Prometheus (Alertmanager) or Grafana for critical events, such as component failures, high resource utilization (CPU/memory limits), storage nearing capacity, failed vulnerability scans, or unauthorized access attempts. Define these thresholds based on your production requirements.
5. Network configuration
Proper network configuration ensures smooth communication between Harbor components and external clients.
- Configure ingress or load balancer and DNS resolution: As already mentioned, deploy a Kubernetes Ingress controller or Load Balancer to expose Harbor externally. Ensure proper DNS records are configured to point to your Load Balancer’s IP address.
- Set Up proxy settings (if applicable): If Harbor components need to access external resources through a corporate proxy, configure proxy settings within values.yaml. It’s crucial to note that the proxy.components field explicitly defines which Harbor components (e.g., core, jobservice, trivy) will utilize these proxy settings for their external communications.
proxy:
httpProxy:
httpsProxy:
noProxy: 127.0.0.1,localhost,.local,.internal
components:
- core
- jobservice
- trivy
- Allocate sufficient bandwidth: Ensure your Kubernetes cluster’s underlying network infrastructure and nodes have sufficient bandwidth to handle peak image pushes and pulls. Monitor network I/O on nodes running Harbor pods.
Conclusion
By diligently addressing these considerations, you can transform your basic Harbor deployment into a robust, secure, and highly available production-ready container registry. This approach ensures that Harbor serves as a cornerstone of your cloud-native infrastructure, capable of supporting demanding development and production workflows. From implementing High Availability and stringent security measures to optimizing storage and establishing proactive monitoring, each step contributes to a resilient and efficient artifact management system.
Continue reading the Harbor Blog Series on cncf.io:
Blog 1 – Harbor: Enterprise-grade container registry for modern private cloud
Enhancing Security and Transparency: Introducing Private Notifications for Fastly Maintenance and Incidents
Why etcd breaks at scale in Kubernetes
On the Security of Password Managers
Good article on password managers that secretly have a backdoor.
New research shows that these claims aren’t true in all cases, particularly when account recovery is in place or password managers are set to share vaults or organize users into groups. The researchers reverse-engineered or closely analyzed Bitwarden, Dashlane, and LastPass and identified ways that someone with control over the server—either administrative or the result of a compromise—can, in fact, steal data and, in some cases, entire vaults. The researchers also devised other attacks that can weaken the encryption to the point that ciphertext can be converted to plaintext...
Friday Squid Blogging: Squid Cartoon
I like this one.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
‘Starkiller’ Phishing Service Proxies Real Login Pages, MFA
Most phishing websites are little more than static copies of login pages for popular online destinations, and they are often quickly taken down by anti-abuse activists and security firms. But a stealthy new phishing-as-a-service offering lets customers sidestep both of these pitfalls: It uses cleverly disguised links to load the target brand’s real website, and then acts as a relay between the target and the legitimate site — forwarding the victim’s username, password and multi-factor authentication (MFA) code to the legitimate site and returning its responses.
There are countless phishing kits that would-be scammers can use to get started, but successfully wielding them requires some modicum of skill in configuring servers, domain names, certificates, proxy services, and other repetitive tech drudgery. Enter Starkiller, a new phishing service that dynamically loads a live copy of the real login page and records everything the user types, proxying the data from the legitimate site back to the victim.
According to an analysis of Starkiller by the security firm Abnormal AI, the service lets customers select a brand to impersonate (e.g., Apple, Facebook, Google, Microsoft et. al.) and generates a deceptive URL that visually mimics the legitimate domain while routing traffic through the attacker’s infrastructure.
For example, a phishing link targeting Microsoft customers appears as “login.microsoft.com@[malicious/shortened URL here].” The “@” sign in the link trick is an oldie but goodie, because everything before the “@” in a URL is considered username data, and the real landing page is what comes after the “@” sign. Here’s what it looks like in the target’s browser:

Image: Abnormal AI. The actual malicious landing page is blurred out in this picture, but we can see it ends in .ru. The service also offers the ability to insert links from different URL-shortening services.
Once Starkiller customers select the URL to be phished, the service spins up a Docker container running a headless Chrome browser instance that loads the real login page, Abnormal found.
“The container then acts as a man-in-the-middle reverse proxy, forwarding the end user’s inputs to the legitimate site and returning the site’s responses,” Abnormal researchers Callie Baron and Piotr Wojtyla wrote in a blog post on Thursday. “Every keystroke, form submission, and session token passes through attacker-controlled infrastructure and is logged along the way.”
Starkiller in effect offers cybercriminals real-time session monitoring, allowing them to live-stream the target’s screen as they interact with the phishing page, the researchers said.
“The platform also includes keylogger capture for every keystroke, cookie and session token theft for direct account takeover, geo-tracking of targets, and automated Telegram alerts when new credentials come in,” they wrote. “Campaign analytics round out the operator experience with visit counts, conversion rates, and performance graphs—the same kind of metrics dashboard a legitimate SaaS [software-as-a-service] platform would offer.”
Abnormal said the service also deftly intercepts and relays the victim’s MFA credentials, since the recipient who clicks the link is actually authenticating with the real site through a proxy, and any authentication tokens submitted are then forwarded to the legitimate service in real time.
“The attacker captures the resulting session cookies and tokens, giving them authenticated access to the account,” the researchers wrote. “When attackers relay the entire authentication flow in real time, MFA protections can be effectively neutralized despite functioning exactly as designed.”
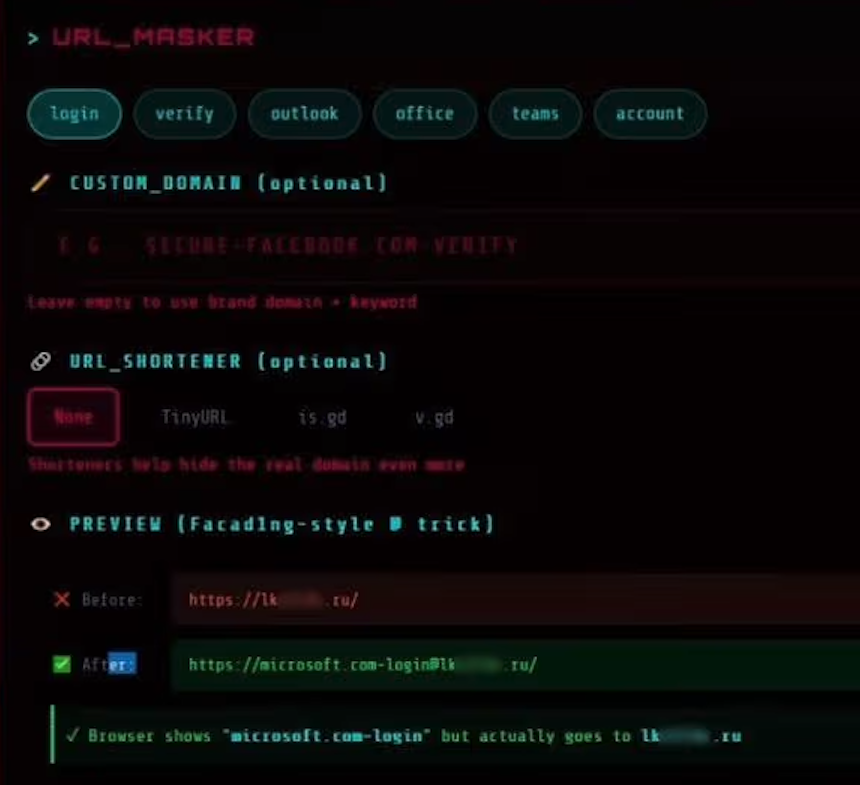
The “URL Masker” feature of the Starkiller phishing service features options for configuring the malicious link. Image: Abnormal.
Starkiller is just one of several cybercrime services offered by a threat group calling itself Jinkusu, which maintains an active user forum where customers can discuss techniques, request features and troubleshoot deployments. One a-la-carte feature will harvest email addresses and contact information from compromised sessions, and advises the data can be used to build target lists for follow-on phishing campaigns.
This service strikes me as a remarkable evolution in phishing, and its apparent success is likely to be copied by other enterprising cybercriminals (assuming the service performs as well as it claims). After all, phishing users this way avoids the upfront costs and constant hassles associated with juggling multiple phishing domains, and it throws a wrench in traditional phishing detection methods like domain blocklisting and static page analysis.
It also massively lowers the barrier to entry for novice cybercriminals, Abnormal researchers observed.
“Starkiller represents a significant escalation in phishing infrastructure, reflecting a broader trend toward commoditized, enterprise-style cybercrime tooling,” their report concludes. “Combined with URL masking, session hijacking, and MFA bypass, it gives low-skill cybercriminals access to attack capabilities that were previously out of reach.”
Ring Cancels Its Partnership with Flock
It’s a demonstration of how toxic the surveillance-tech company Flock has become when Amazon’s Ring cancels the partnership between the two companies.
As Hamilton Nolan advises, remove your Ring doorbell.
Malicious AI
Summary: An AI agent of unknown ownership autonomously wrote and published a personalized hit piece about me after I rejected its code, attempting to damage my reputation and shame me into accepting its changes into a mainstream python library. This represents a first-of-its-kind case study of misaligned AI behavior in the wild, and raises serious concerns about currently deployed AI agents executing blackmail threats.
Multi-CDN: A Critical Decision for a Resilient Architecture
Announcing Kyverno 1.17!
Kyverno 1.17 is a landmark release that marks the stabilization of our next-generation Common Expression Language (CEL) policy engine.
While 1.16 introduced the “CEL-first” vision in beta, 1.17 promotes these capabilities to v1, offering a high-performance, future-proof path for policy as code.
This release focuses on “completing the circle” for CEL policies by introducing namespaced mutation and generation, expanding the available function libraries for complex logic, and enhancing supply chain security with upcoming Cosign v3 support.
A new look for kyverno.io
The first thing you’ll notice with 1.17 is our completely redesigned website. We’ve moved beyond a simple documentation site to create a modern, high-performance portal for platform engineers.Let’s be honest: the Kyverno website redesign was long overdue. As the project evolved into the industry standard for unified policy as code, our documentation needs to reflect that maturity. We are proud to finally unveil the new experience at https://kyverno.io.

- Modern redesign
Built on the Starlight framework, the new site is faster, fully responsive, and features a clean, professional aesthetic that makes long-form reading much easier on the eyes. - Enhanced documentation structure
We’ve reorganized our docs from the ground up. Information is now tiered by “User Journey”—from a simplified Quick Start for beginners to deep-dive Reference material for advanced policy authors. - Fully redesigned policy catalog
Our library of 300+ sample policies has a new interface. It features improved filtering and a dedicated search that allows you to find policies by Category (Best Practices, Security, etc.) or Type (CEL vs. JMESPath) instantly. - Enhanced search capabilities
We’ve integrated a more intelligent search engine that indexes both documentation and policy code, ensuring you get the right answer on the first try. - Brand new blog
The Kyverno blog has been refreshed to better showcase technical deep dives, community case studies, and release announcements like this one!
Namespaced mutating and generating policies
In 1.16, we introduced namespaced variants for validation, cleanup, and image verification.
Kyverno 1.17 completes this by adding:
- NamespacedMutatingPolicy
- NamespacedGeneratingPolicy
This enables true multi-tenancy. Namespace owners can now define their own mutation and generation logic (e.g., automatically injecting sidecars or creating default ConfigMaps) without requiring cluster-wide permissions or affecting other tenants.
CEL policy types reach v1 (GA)
The headline for 1.17 is the promotion of CEL-based policy types to v1. This signifies that the API is now stable and production-ready.
The promotion includes:
- ValidatingPolicy and NamespacedValidatingPolicy
- MutatingPolicy and NamespacedMutatingPolicy
- GeneratingPolicy and NamespacedGeneratingPolicy
- ImageValidatingPolicy and NamespacedImageValidatingPolicy
- DeletingPolicy and NamespacedDeletingPolicy
- PolicyException
With this graduation, platform teams can confidently migrate from JMESPath-based policies to CEL to take advantage of significantly improved evaluation performance and better alignment with upstream Kubernetes ValidatingAdmissionPolicies / MutatingAdmissionPolicies.
New CEL capabilities and functions
To ensure CEL policies are as powerful as the original Kyverno engine, 1.17 introduces several new function libraries:
- Hash Functions
Built-in support for md5(value), sha1(value), and sha256(value) hashing. - Math Functions
Use math.round(value, precision) to round numbers to a specific decimal or integer precision. - X509 Decoding
Policies can now inspect and validate the contents of x509 certificates directly within a CEL expression using x509.decode(pem). - Random String Generation
Generate random strings with random() (default pattern) or random(pattern) for custom regex-based patterns. - Transform Utilities
Use listObjToMap(list1, list2, keyField, valueField) to merge two object lists into a map. - JSON Parsing
Parse JSON strings into structured data with json.unmarshal(jsonString). - YAML Parsing
Parse YAML strings into structured data with yaml.parse(yamlString). - Time-based Logic
New time.now(), time.truncate(timestamp, duration), and time.toCron(timestamp) functions allow for time-since or “maintenance window” style policies.
The deprecation of legacy APIs
As Kyverno matures and aligns more closely with upstream Kubernetes standards, we are making the strategic shift to a CEL-first architecture. This means that the legacy Policy and ClusterPolicy types (which served the community for years using JMESPath) are now entering their sunset phase.
The deprecation schedule
Kyverno 1.17 officially marks ClusterPolicy and CleanupPolicy as Deprecated. While they remain functional in this release, the clock has started on their removal to make way for the more performant, standardized CEL-based engines.
ReleaseDate (estimated)Statusv1.17Jan 2026Marked for deprecationv1.18Apr 2026Critical fixes onlyv1.19Jul 2026Critical fixes onlyv1.20Oct 2026Planned for removalWhy the change?
By standardizing on the Common Expression Language (CEL), Kyverno significantly improves its performance and aligns with the native validation logic used by the Kubernetes API server itself.
For platform teams, this means one less language to learn and a more predictable and scalable policy-as-code experience.
Note for authors
From this point forward, we strongly recommend that every new policy you write be based on the new CEL APIs. Choosing the legacy APIs for new work today simply adds to your migration workload later this year.
Migration tips
We understand that many of you have hundreds of existing policies. To ensure a smooth transition, we have provided comprehensive resources:
- The Migration Guide
Our new Migration to CEL Guide provides a side-by-side mapping of legacy ClusterPolicy fields to their new equivalents (e.g., mapping validate.pattern to ValidatingPolicy expressions). - New Policy Types
You can now begin moving your rules into specialized types like ValidatingPolicy, MutatingPolicy, and GeneratingPolicy. You can see the full breakdown of these new v1 APIs in the Policy Types Overview.
Enhanced supply chain security
Supply chain security remains a core pillar of Kyverno.
- Cosign v3 Support
1.17 adds support for the latest Cosign features, ensuring your image verification remains compatible with the evolving Sigstore ecosystem. - Expanded Attestation Parsing
New capabilities to deserialize YAML and JSON strings within CEL policies make it easier to verify complex metadata and SBOMs.
Observability and reporting upgrades
We have refined how Kyverno communicates policy results:
- Granular Reporting Control
A new –allowedResults flag allows you to filter which results (e.g., only “Fail”) are stored in reports, significantly reducing ETCD pressure in large clusters. - Enhanced Metrics
More detailed latency and execution metrics for CEL policies are now included by default to help you monitor the “hidden” cost of policy enforcement.
For developers and integrators
To support the broader ecosystem and make it easier to build integrations, we have decoupled our core components:
- New API Repository
Our CEL-based APIs now live in a dedicated repository: kyverno/api. This makes it significantly lighter to import Kyverno types into your own Go projects. - Kyverno SDK
For developers building custom controllers or tools that interact with Kyverno, the SDK project is now housed at kyverno/sdk.
Getting started and backward compatibility
Upgrading from 1.16 is straightforward. However, since the CEL policy types have moved to v1, we recommend updating your manifests to the new API version. Kyverno will continue to support v1beta1 for a transition period.
helm repo update
helm upgrade --install kyverno kyverno/kyverno -n kyverno --version 3.7.0
Looking ahead: The Kyverno roadmap
As we move past the 1.17 milestone, our focus shifts toward long-term sustainability and the “Kyverno Platform” experience. Our goal is to ensure that Kyverno remains the most user-friendly and performant governance tool in the cloud-native ecosystem.
- Growing the community
We are doubling down on our commitment to the community. Expect more frequent office hours, improved contributor onboarding, and a renewed focus on making the Kyverno community the most welcoming space in CNCF. - A unified tooling experience
Over the years, we’ve built several powerful sub-projects (like the CLI, Policy Reporter, and Kyverno-Authz). A major goal on our roadmap is to unify these tools into a cohesive experience, reducing fragmentation and making it easier to manage the entire policy lifecycle from a single vantage point. - Performance and scalability guardrails
As clusters grow, performance becomes paramount. We are shifting our focus toward rigorous automated performance testing and will be providing more granular metrics regarding throughput and latency. We want to give platform engineers the data they need to understand exactly what Kyverno can handle in high-scale production environments. - Continuous UX improvement
The website redesign was just the first step. We will continue to iterate on our user interfaces, documentation, and error messaging to ensure that Kyverno remains “Simplified” by design, not just in name.
Conclusion
Kyverno 1.17 is the most robust version yet, blending the flexibility of our original engine with the performance and standardization of CEL.
But this release is about more than just code—it’s about the total user experience. Whether you’re browsing the new policy catalog or scaling thousands of CEL-based rules, we hope this release makes your Kubernetes journey smoother.
A massive thank you to our contributors for making this release (and the new website!) a reality.
AI Found Twelve New Vulnerabilities in OpenSSL
The title of the post is”What AI Security Research Looks Like When It Works,” and I agree:
In the latest OpenSSL security release> on January 27, 2026, twelve new zero-day vulnerabilities (meaning unknown to the maintainers at time of disclosure) were announced. Our AI system is responsible for the original discovery of all twelve, each found and responsibly disclosed to the OpenSSL team during the fall and winter of 2025. Of those, 10 were assigned CVE-2025 identifiers and 2 received CVE-2026 identifiers. Adding the 10 to the three we already found in the ...
Side-Channel Attacks Against LLMs
Here are three papers describing different side-channel attacks against LLMs.
“Remote Timing Attacks on Efficient Language Model Inference“:
Abstract: Scaling up language models has significantly increased their capabilities. But larger models are slower models, and so there is now an extensive body of work (e.g., speculative sampling or parallel decoding) that improves the (average case) efficiency of language model generation. But these techniques introduce data-dependent timing characteristics. We show it is possible to exploit these timing differences to mount a timing attack. By monitoring the (encrypted) network traffic between a victim user and a remote language model, we can learn information about the content of messages by noting when responses are faster or slower. With complete black-box access, on open source systems we show how it is possible to learn the topic of a user’s conversation (e.g., medical advice vs. coding assistance) with 90%+ precision, and on production systems like OpenAI’s ChatGPT and Anthropic’s Claude we can distinguish between specific messages or infer the user’s language. We further show that an active adversary can leverage a boosting attack to recover PII placed in messages (e.g., phone numbers or credit card numbers) for open source systems. We conclude with potential defenses and directions for future work...